05.09.07
Posted in Hacking, programmer productivity, robobait at 1:50 pm by ducky
I’m starting to look at a bunch of software engineering tools, particularly those that purport to help debugging. One is javaspider, which is a graphical way of inspecting complex objects in Eclipse. It looks interesting, but which has almost no documentation on the Web. I’m not sure that it’s something I would use a lot, but in the spirit of making it easier to find things, here is a link to a brief description of how to use javaspider.
Keywords for the search engines: manual docs instructions javaspider inspect objects Eclipse
Permalink
05.08.07
Posted in programmer productivity at 10:41 pm by ducky
A theme in Andrew Ko’s papers (which I’ve read a lot of recently) is that a lot of the problems that programmers have is due to making invalid hypotheses. For example, in Designing the Whyline, (referring to an earlier paper, which I didn’t read closely), they say “50% of all errors were due to programmers’ false assumptions in the hypotheses they formed while debugging existing errors.”
It seemed that chasing down an incorrect hypothesis could also chew up a lot of time. I suspect that when coders get stuck, it’s because they have spent too long chasing down the wrong trail.
Yesterday, I had two friends take a quick, casual look at some code to see if they could quickly find where certain output was written out. Both worked forward in the code, starting at main() and tracing through calls to see where control went. At one point in the source, there were three different paths that they could have chosen to trace. The first person chose to follow statement A; the second person chose to follow statement B. Both were reasonable choices, but A happened to be the correct one.
The first person took ten minutes, while the second person spent 30 minutes running off into the weeds chasing statement B. (He eventually gave up, backtracked, and took about ten minutes following statement A to the proper location.)
Implications for programmer productivity measures
The second person took four times as long as the first to complete the task. Was the first person a four times “better” programmer? I don’t think so. From my looking at the code, the second person made a completely legitimate choice. I’m quite happy to believe that on some other task, the first person might make the wrong choice at first and the second person make the right choice.
This makes me even more suspicious of people claiming that there is a huge productivity difference among programmers. The controlled studies that I have seen have all had a very small number of tasks, far too few to make significant generalizations about someone’s long-term abilities.
Furthermore, I think there is sample bias. For a user study, you have to have very simple problems so that people have a chance to finish the allotted tasks in a few hours or less. That favors people who do “breadth-first” analyses of code; who spend a tiny bit of time on one hypothesis, and if that doesn’t quickly give results, move on to the next one.
However, sometimes problems really are gnarly and hairy, and you really do have to stick to one hypothesis for a long time. People who are good at sticking to the one hypothesis through to resolution (without getting discouraged) have value that wouldn’t necessarily be recognized in an academic user study of programmer speed.
How can we reduce false hypotheses?
After a binge of reading Andrew Ko papers last week, I decided to start forcing myself to write down three hypotheses every time I had to make a guess as to why something happened.
In my next substantive coding session, there were four bugs that I worked on. For two of them, I thought of two hypotheses quickly, but then was stumped for a moment as to what I could put for a third… so I put something highly unlikely. In once case, for example, I hypothesized a bug in code that I hadn’t touched in weeks.
Guess what? In both of those cases, it was the “far-fetched” hypothesis that turned out to be true! For example, there was a bug in the code that I hadn’t touched in weeks: I had not updated it to match some code that I’d recently refactored.
While it’s too early for me to say what the long-term effect of writing down three hypotheses will be, in the limited coding I’ve done since I started, it sure feels like I’m doing a much better job of debugging.
Permalink
05.03.07
Posted in programmer productivity at 10:38 am by ducky
As a followup to my previous post about debugging tools, I realized that you could pretty easily add a feature to an IDE that could automatically and very quickly find where hangs were taking place for a certain class of hangs.
What causes hangs?
Hangs happen when something doesn’t stop when it should. This means either
- a loop control structure (for, while, etc) has a test that never is FALSE, so it never stops
- a recursive call doesn’t terminate
- a resource is busy
Let’s look at the loop control case first. It is hugely interesting to figure out the location of the boundary between code that is in the loop and code that is not in the loop. The “lowest” (where main is at the absolute bottom) stack frame that is in the loop will be where the test is not getting the right boolean value, and that’s where you want to start debugging.
For a recursive call, the location in the stack keeps changing, but the same lines of code keep getting executed. Again, the “lowest” frame that is in the loop will be where the recursive structure gets kicked off. Again, that’s an interesting place to start debugging.
If you are hanging because of a resource — a lock or a network connection or something like that — is busy then popping into the debugger should show you exactly where the code is blocked. I don’t have an idea for how to improve the process of finding that because it’s pretty simple.
Tool enhancement
So how do you find the boundary between in and out of the loop?
- Start running in the debugger; pause manually when you are pretty sure you are in the hang.
- Press a “do magic” button.
- Have the IDE set breakpoints at all current lines in all current frames. Set a timeout timer to 0.
- Have the IDE resume execution.
- If execution hits a breakpoint, have it remove the breakpoint, reset the timer and go to step 4.
- If the timeout timer reaches a certain value (1 sec? 5 sec? this will depend upon the problem; the user will need to set this), pause execution again.
- The frame above the top frame that has a breakpoint set will be the frame that has the incorrect loop test. The IDE magic should put the user into the frame above the top frame that has a breakpoint.
This should be relatively easy to do. Again, I’m tempted to do it, but worried about taking time away from other things.
Permalink
04.25.07
Posted in programmer productivity at 1:05 pm by ducky
I read yet another paper by Andrew Ko, this one titled Information Needs in Collocated Software Development Teams and co-authored by Gina Venolia and Robert DeLine.
They collected a bunch of data by shadowing developers of various sorts and got about 25 hrs of data out of it. Mostly they were interested in what kinds of information people need and use, but as a side effect they also logged how much time was spent on what type of activity.
I was curious about how much time people spent on what activity, but they didn’t publish the breakdowns. I can completely understand that — the classification was probably subjective, the sample might have been skewed, blah blah blah. It wouldn’t have had much academic validity.
Still, it is interesting from a non-academic standpoint. It’s another piece of information that helps me create my model of the world. Thus I eyeballed times from a chart in the paper, and this my very imprecise view of how that group of non-randomly-selected developers spent their time:
- 19% – understanding execution behavior (reading code, using the debugger, asking co-workers)
- 18% – writing code
- 15% – reproducing a failure (reading bug reports, setting up test machines, running code)
- 13% – triaging bugs (thinking, talking with other developers)
- 11% – reasoning about design e.g. what is this code supposed to do? (thinking, asking others)
- 10% – non-work
- 8% – maintaining awareness (reading bug reports, reading submission reports, reading email)
- 6% – submitting a change (making sure submission was correct, diffing, running unit tests, using debuggers)
Note that they didn’t define what “non-work” meant. Did writing docs count as work? Did helping marketing out count as work? Did helping a teammate count?
While the numbers seem reasonable if I think about it, if you had asked me how much time was spent on submissions and on triaging bugs, I would have given much smaller numbers. That was surprising to me.
These numbers also show that what one learns in school — how to write a piece of code from scratch — is only a very small portion of what one spends time on in The Real World. While I hear a lot of angst from educators about “communication skills”, I have never seen a class on how to write a good bug report, or how to write a good submission report. I wouldn’t have ever heard of classes on how to write good email messages if I didn’t happen to be a recognized authority on that.
I also haven’t seen much training on how to use a debugger, how to reproduce bugs, or how to triage bugs. Maybe there isn’t much you can teach people on reproducing bugs or triaging them, but there certainly is a lot you can teach people about how to use a debugger.
NB: I was surprised to see that there were nine phone calls in the 25 hours of observation, three of which were work-related. I didn’t know anybody still made phone calls in 2006! I probably got about two work-related phone calls per year in the past four years, and my cell phone log shows that I only get about ten phone calls total per month. The bulk of my communication is email, IM, and SMS.
Permalink
04.24.07
Posted in programmer productivity, review at 2:12 pm by ducky
I’m reading A framework and methodology for studying the causes of software errors in programming systems by Ko and Myers that classifies the causes of software errors, and there is a diagram (Figure 4) that I’m really taken with. They talk about there being three different kinds of breakdowns: skill breakdowns (what I think of as “unconscious” errors, like typos), rule breakdowns (using the wrong approach/rule, perhaps because of a faulty assumption or understanding), and knowledge breakdowns (which usually reflect limitations of mental abilities like inability to hold all the problem space in human memory at one time).
Leaving out the breakdowns, the diagram roughly looks like this:
| Specification activities |
| Action |
Interface |
Information |
| Create |
Docs |
Requirement specifications |
| Understand |
Diagrams |
Design specifications |
| Modify |
Co-workers |
|
| Implementation activities |
| Action |
Interface |
Information |
| Explore |
Docs |
Existing architecture |
| Design |
Diagrams |
Code libraries |
| Reuse |
Online help |
Code |
| Understand |
Editor |
|
| Create |
|
|
| Modify |
|
|
| Runtime (testing and debugging) activities |
| Action |
Interface |
Information |
| Explore |
Debugger |
Machine behavior |
| Understand |
Output devices |
Program behavior/td> |
| Reuse |
Online help |
Code |
I’m a bit fuzzy on what exactly the reuse “action” is, and how “explore” and “understand” are different, but in general, it seems like a good way to describe programming difficulties. I can easily imagine using this taxonomy when looking at my user study.
Permalink
04.23.07
Posted in Hacking, programmer productivity, Technology trends at 1:31 pm by ducky
I recently watched some people debugging, and it seemed like a much harder task than it should have been. It seems like inside an IDE, you ought to be able to click START LOGGING, fiddle some with the program of interest, click STOP LOGGING, and have it capture information about how many times each method was hit.
Then, to communicate that information to the programmer, change the presentation of the source code. If a routine was never executed, don’t show it in the source (or color it white). If none of a class’ methods or fields were executed, don’t show that class/file. If a method was called over and over again, make it black. If it was hit once, make it grey.
It doesn’t need to be color. You could make frequent classes/methods bigger and infrequent ones smaller. If the classes/methods that were never changed were just not displayed — not visible in the Package Explorer in Eclipse, for example — that would be a big help.
Permalink
02.16.07
Posted in programmer productivity, review at 5:12 pm by ducky
I got started on looking at productivity variations again and just couldn’t stop. I found Programmer performance and the effects of the workplace by DeMarco and Lister (yes, the authors of Peopleware). The paper is well worth a read.
In their study, they had 83 pairs of professional programmers work all on the same well-specified programming problem using their normal language tools in their normal office environment. Each pair was two people from the same company, but they were not supposed to work together.
- They found a strong correlation between the two halves of a company pair, which may be in part from
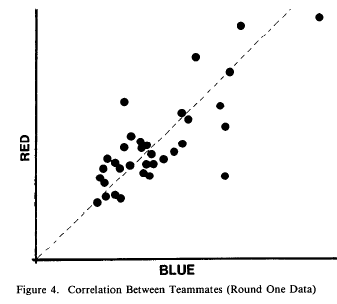
- a pretty stunning correlation between the office environment and productivity
- (or perhaps due to different companies having radically different tools/libraries/languages/training/procedures, which they didn’t discuss)
- The average time-to-complete was about twice the fastest time-to-complete.
- Cobol programmers as a group took much longer to finish than the other programmers. (Insert your favorite Cobol joke here.)
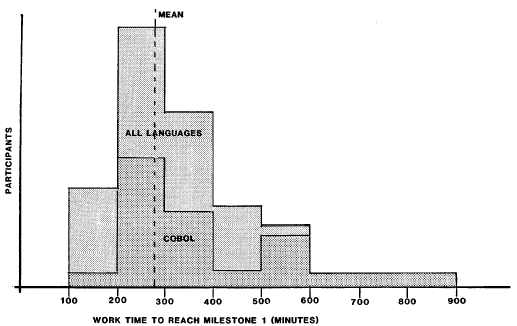
Over and over, I keep seeing that the median time to complete a single task is on the order of 2x to 4x times the fastest, not 100x. This study seems to imply that a great deal of that difference is due not to the individual’s inherent capabilities, but rather the environment where they work.
Permalink
Posted in programmer productivity, review at 4:17 pm by ducky
To reiterate, there’s a paper by Sackman et al from 1966 that people have seized upon to show a huge variation in programmer productivity, a paper by Dickey in 1981 that refuted Sackman pretty convincingly, and an article by Curtis in the same issue as Dickey’s. I didn’t talk much about the Dickey paper, but Tony Bowden has a good blog posting on the Dickey paper, where Dickey reports on a more reasonable interpretation of numbers from the Sackman’s data.
(Basically, Sackman compared the time it took to complete a task using a batch system against the time it took using a timeshare system. This was interesting in 1966 when they were trying to quantify the benefit of timeshare systems, but it’s not good to look at those numbers and say, “Ah, see, there is a huge variation in programmers!”)
Because I like making pretty histograms, here are the Sackman numbers via Dickey via Bowden — the way they ought to be interpreted. These show the time to complete for two tasks, the “Algebra” task and the “Maze” task.


The small sample size hurts, but (as in the Curtis data and the Ko data) I don’t see an order of magnitude difference in completion speed.
Permalink
02.15.07
Posted in programmer productivity, review at 6:18 pm by ducky
(See my previous programmer productivity article for some context.)
Martin Robillard did a study in conjunction with my advisor. In it, he had five programmers work on a relatively complex task for two hours. Two of the programmers finished in a little over an hour, one finished in 114 minutes, and two did not finish in two hours:

Robillard carefully looked at five subtasks that were part of doing the main task; there was a very sharp distinction between the three who finished and the two who did not. The two who didn’t finish only got one of the subtasks “right”. S for “Success” means everything worked. I for “Inelegant” means it worked but was kind of kludgy. B for “Buggy” means that there were cases where it didn’t work; U for “Unworkable” means that it usually didn’t work; NA for “Not Attempted” means they didn’t even try to do that subtask.
| Coder ID |
Time to finish |
Check box |
Disabling |
Deletion |
Recovery |
State reset |
Years exper. |
| #3 |
72 min |
S! |
S! |
S! |
S! |
S! |
5 |
| #2 |
62 min |
S! |
S! |
S! |
S! |
B |
3 |
| #4 |
114 min |
I |
S! |
B |
S! |
B |
5 |
| #1 |
125 min (timed out) |
S! |
U |
U |
U |
NA |
1 |
| #5 |
120 min (timed out) |
S! |
U |
U |
NA |
NA |
1 |
Because coder #1 and coder #5 timed out, I don’t know how much of a conclusion I can draw from this data about what the range of time taken is. From this small sample size, it does look like experience matters.
This study did have some interesting observations:
- Everyone had to spend an hour looking at the code before they started making changes. Some spent this exploration period writing down what they were going to change, then followed that script during the coding phase. The ones who did were more successful than the ones who didn’t.
- The more successful coders (#2 and #3) spread their changes around as appropriate. The others tried to make all of the changes in one place.
- The more successful coders looked at more methods, and they were more directed about which ones they looked at. The second column in the table below is a ratio of the number of methods that they looked at via cross-references and keyword searching over the total number of methods that they looked at. The less-successful coders found their methods more frequently by scrolling, browsing, and returning to an already-open window.
| Coder ID |
Number of methods examined |
intent-driven:total ratio |
Time to finish |
| #3 |
34 |
31.7% |
72 min |
| #2 |
27.5 |
23.3% |
62 min |
| #4 |
27.5 |
30.8% |
114 min |
| #1 |
8.5 |
2.0% |
125 min (timed out) |
| #5 |
17.5 |
10.7% |
120 min (timed out) |
- From limited data, they conclude that skimming the source isn’t very useful — that if you don’t know what you are looking for, you won’t notice it when it passes your eyeballs.
Permalink
12.17.06
Posted in programmer productivity at 10:16 pm by ducky
What factors go into programmer productivity? I’ve been thinking about that a lot lately.
My recent reflections on the Curtis results and reflections on the Ko et al results of experiments of programmer productivity have focused on one narrow slice, what I call “hands-on-keyboard”. Hands-on-keyboard productivity is measured by how fast someone who is given a small, well-defined task can do that task. As I mentioned in those two blog posts, it is hard to measure even that simple thing.
In the wild, there are a huge number of factors that don’t bear on the types of experiments that Curtis and Ko et al did:
- How much time does the coder spend actually working? If Jane buries her nose in a keyboard for 60 hours per week, while Fred is only at work on an average of 38 hours every week, plus spends 15 hours goofing off away from his desk (talking at the water cooler/playing pool/reading on the john), 15 hours reading email, and 8 hours surfing the Web, then it is highly likely that Jane will be more productive than Fred.
- How much work time does the coder spend on writing code? If Bill’s company has a lot of bureaucratic overhead, and/or he writes a lot of documentation, serves on the Emergency Response Team, gathers requirements from the customers, explains the limitations to marketing, etc, then even if Bill works 60 hours per week, he’s probably not going to be as productive as nose-in-keyboard Jane.
- How much coding time does the coder spend on the right code for the project? If Joe spends a lot of time to make the least-often-run method run 10% faster, then that will be less useful than if he spent the time making the most-often-run method run 10% faster. Note that inefficiencies can come either from Joe or his management. Management might give direct orders to work on something useless; Joe might disobey sensible orders from management.
- How much time does the coder spend on the right project? If George’s project gets cancelled and Jane’s doesn’t, then Jane’s contribution will be more valuable.
- How well does the coder design? The problems that Curtis and Ko et al gave were all quite small and built upon a pre-existing code base. While there are many tasks which only require modifying an existing code base, there are very few programming jobs that don’t demand any design. Being able to map out a good design makes the implementation much, much easier.
- What damage does the coder leave in his/her wake? If Brian aggravates people so much that Brian’s boss has to spend a lot of time on damage control, while Jane is totally inoffensive, then Jane will probably be more valuable. Brian has a negative productivity penalty that has to get paid along with the positive work that he does.
All of these things are very important — perhaps more important than the hands-on-keyboard productivity. I am starting to lose faith that differences in programmer productivity can be measured in a meaningful way. 🙁
Permalink
« Previous Page — « Previous entries « Previous Page · Next Page » Next entries » — Next Page »
