11.02.08
Posted in review, Technology trends at 8:44 pm by ducky
Ken Church and James Hamilton have a blog posting of Diseconomies of Scale which doesn’t seem right to me.
They suggest that it is more expensive to run a data center than to buy a bunch of condos, put 48 servers in each, wall up the servers, rent out the condo, and use the servers as a distributed data farm.
Capital costs
Church and Hamilton figure that the capital cost of a set of condos is about half of the cost of a data center. However, they use a sales price of $100K for the condos, but according to a news release issued by the US National Association of Realtors, the median metro-area condo price in the US was $226,800 in 2007 Q2.
Perhaps you could get cheaper condos by going outside the major metro areas, but you might not be able to get as good connectivity outside the major metro areas. I don’t have a figure for the median condo price in cities of population between 50,000 and 100,000, but that would be an interesting number.
A rack of 48 servers draws 12kW (at 250W/server, his number). For a house wired for 110V, this means that the current draw would be 109A. That is approximately five times what a normal household outlet can carry, so you would need to do significant rewiring. I don’t have an estimate on that cost.
Furthermore, my construction-industry source says that most houses can’t stand that much extra load. He says that older houses generally have 75A fuseboxes; newer houses have 100A to them. He says that it is becoming more common for houses to get 200A fuseboxes, but only for the larger houses.
While it is possible to upgrade, “ the cost of [upgrading from a 100A fusebox to a 200A fusebox] could be as high as $2000.” I suspect that an upgrade of this size would also need approval from the condo board (and in Canada, where residential marijuana farms is somewhat common, suspicion from the local police department).
If, as Church and Hamilton suggest, you “wall in” the servers, then you will need to do some planning and construction to build the enclosure for the servers. I can’t imagine that would cost less than $1000, and probably more like $2000.
They also don’t figure in the cost to pay someone (salary+plane+rental car+hotel) to evaluate the propterties, bid on them, and buy them. I wouldn’t be surprised if this would add $10K to each property. While there are also costs associated with acquiring property for one large data center, those costs should be lower than for aquiring a thousand condo.
Bottom line: I believe the capital costs would be higher than they expect.
Operating costs
For their comparison, Church and Hamilton put 54,000 servers either in one data center or in 1125 condos. They calculate that the power cost for the data center option is $3.5M/year. By contrast, they figure that the condo power consumption is $10.6M/year, but is offset by $800/month in condo rental income at 80% occupancy, for $8.1M in income. I calculate that 800*1125*12*.8 is $8.6M, and will use that number, giving a net operating cost of $2M/year, or $1.5M/year less than a data center.
Given a model with 1125 condos, this works out to $111 per condo per month. Put another way, if they are off by $111/month, a data center is cheaper.
Implicit in their model is that nobody will ever have to lay hands on a server rack. If you have to send someone out to someone’s residence to reboot the rack, that will cost you. That will depend upon how far the condo is from the technician’s normal location, how easy it is to find the condo, how agreeable the tenant is to having someone enter their condo, etc. I believe this would be a number significantly larger than zero. You might be able to put something in the lease about how the tenant agrees to reboot the servers on request, but this inconvenience will come at some price. Either it will come in the form of reduced monthly rent or a per-incident payment to the tenant.
I believe that the $800/month rental income ($1000/month rent less $200/month condo dues) is overly optimistic.
The median rent for a metro-area apartment was $1324 in 2007, but that’s for all housing types, not just condos. The median rent nationally in 2007 was $665. If you want the metro income, you need to pay the metro purchase price of $227K; if you want to save money by going outside the metro areas, you won’t get the high rent.
Eyeballing a few cities on Craigslist, it looked to me like the metro rent for two-bedroom condos was about $800/month.
Church and Hamilton also didn’t account for
- management fees (~5-7% of gross rent per month, or $50-$70 on income of $1000)
- property taxes (~2%/year of purchase price, so $160/month if he finds condos for $100K)
- maintenance that isn’t covered by the condo association like paint, new carpeting, and the hole the tenant punched in the wall ($40/month)
- reduction in rent for part of the condo being walled off and/or inconvenience of rebooting the servers (~$50/month)
- Liability insurance. If a short in the servers burns the condo complex down, that’s bad.
- Internet connectivity
While they didn’t account for Internet connectivity in either the datacenter scenario or the condos scenario, this is an area wherethere seem to be large economies of scale. For example, a T3 (44.736 Mbit/s) seems to cost between $7,500 and $14K/month or between $167 and $312/Mbit/sec/month. A T1 (1.536 Mbit/s) seems to cost between $550 and $1200/month or between $358 and $781/Mbit/s/month. The T1 is thus about twice as expensive per byte as the T3. I don’t know how much connectivity 54,000 servers would need, but I expect it would be significant, and expect that it would be significantly more expensive in 1125 smaller lots.
Non-quantifiable
I can imagine there some significant additional costs in time and/or money.
- Obstreperous condo boards. If the condo board passes a rule against having server farms in your unit, you’re screwed.
- Obstreperous zoning boards. If the city decides that the server farm is part of a business, they might get unhappy about it being in a building zoned residential.
- Criminal tenants. What’s to stop your tenants from busting into the server closet and stealing all the servers?
Church and Hamilton close their article by saying, “whenever we see a crazy idea even within a factor of two of what we are doing today, something is wrong”. I think they are correct, and that their analysis is overly simplistic and optimistic.
Permalink
10.30.08
Posted in Art, Canadian life, review at 9:01 pm by ducky
I got a ticket to Interesting Vancouver from Boris Mann, who uh reminded me that I owed him a recap in exchange. That’s a perfectly perfectly reasonable request, but that message didn’t sink in ahead of time, so I didn’t take notes or try very hard to remember. I’ll do a dump on my impressions, but you should note that I seemed to have been grumpy that evening, perhaps because I didn’t have enough dinner.
- James Sherret from AdHack: I was about 10 minutes late, so missed his talk completely.
- Darren Barefoot, laptopbedouin.com: I came in in the middle. Darren was basically waxing rhapsodic about the value/joy of telecommuting from other countries for multiple months at a time. His message seemed to be “go, it’ll be fun, you’ll learn, it won’t cost as much as you think, what do you have to lose?”
- When I was younger, I wouldn’t have found anything at all wrong with that message. I would had little patience for old farts telling me (or anyone) that I should grow up and start being responsible blah blah blah. However, now that I am older and have seen how health issues can trash a life, I would suggest more caution, particularly for people who are citizens of countries without socialized medicine. Part of “being responsible” is saving away the money that you will need for later. When you lose your job. When you can’t work because of your illness. When your partner can’t work. When your mother has a heart attack. When your kid needs rehab. You might be fine now, but someday you won’t be. Running off to live in a third-world country probably increases your risk of illness, complications, accidents, and/or violence at least slightly. It also cuts you off from your family — the same family that you might need to turn to someday.
- Roy Yen, soomo.com: I think Roy was the one who was arguing that our “vertical architecture” (i.e. skyscrapers) was contributing to loneliness and isolation, and that we really needed a public gathering space in Vancouver. He said that Vancouver used to have a big public gathering space, but there was a riot in the 70s and The Powers That Be decided that having a big public gathering space was a Bad Idea, so redeveloped it away. He pointed out that the only public gathering space left is the back side of the Art Gallery, and that the Art Gallery is slated to move to False Creek.
- When he blamed the high-density development for loneliness and isolation, I was kind of stunned. “Has he ever lived in suburbia???” I remember asking myself. I immediately thought of a neighbourhood in Orange County where a friend lived, where I spent a few days once. It was all snout houses, and my friend said that in a year of living there, she had never spoken to a neighbour. I think she maybe hadn’t even seen her immediate neighbours — they drove into their garage, and thence immediately into their house. I am now living in a skyscraper for the first time, and I find the density wonderful: I see people in the elevators, I see people as I walk to the bus stop, I see people as I walk to the grocery store, etc. etc. etc. It feels far more communal than driving to everywhere in a car by myself.
- I did think it was interesting to hear about the bygone public space and to think about the back of the Vancouver Art Gallery being the one public gathering space. However, most of the places that I’ve lived didn’t have public gathering spaces, and somehow we got by.
- James Chutter radarddb.com:
- James’ presentation didn’t have a real obvious thesis statement — I don’t know that I learned anything from his talk, but I remember I enjoyed it. He told the story of his evolution as a storyteller, and in doing so talked about the evolution of the Web.
- Cheryl Stephens, plainlanguage.com: Cheryl is a lawyer and literacy advocate who talked about how widespread the problem of literacy is.
- Cheryl lost my attention very, very quickly. Some combination of her voice level, the microphone level, how far she stood from the mike, and me being in the back of the room (I was late, remember?) meant that I had to exert some effort to understand her words, and I didn’t like her words well enough to pay attention. In particular, early on, she asserted, “There can be no education without literacy.” While I might have been extra grumpy that evening (note my grumpy comments elsewhere), I found that statement offensive. Um, blind people can’t be educated? (NB: Only 3% of the visually impaired students at UBC read Braille. I presume the rest use screen readers.)
- Later, she talked about how widespread illiteracy was, and said that only about 10% of the population could read at a college level. I didn’t know about Canada, but right around half of the US population has attended some college. Um, does that mean that 80% of people in college can’t read at a college level?
- One thing that I did find interesting was her report that the Canadian Supreme Court ruled that explaining something wasn’t enough, that the plaintiffs also had to understand it. (She gave the example of someone being offered counsel, and the perp saying he already had a drug counselor — not realizing that “counsel” meant “lawyer”.)
- I was a little confused as how explaining something verbally related to literacy.
- At the end, she rushed in about thirty seconds of how to make your prose more understandable. I personally would have preferred less talk aimed at convincing me literacy was a problem and more on how to address it.
- Shannon LaBelle, Vancouver Museums: Shannon gave a very quick talk that was basically, “Vancouver has lots of interesting museums, especially the Museum of Anthropology when it reopens, go visit them!”
- Irwin Oostindie, creativetechnology.org: Irwin talked about his community, the Downtown East Side, and in bringing pride to his community through culture, especially in community-generated media.
- I wanted to like Irwin’s lofty goals. He was a very compelling speaker. But I have done a lot of work in community media, and know that it is extremely difficult to make compelling media. It sure seemed like he was getting his hopes up awfully high. Well, best of luck to him. Maybe.
- He seemed to want to make DTES a vibrant, interesting, entertaining place. I worry that if it becomes entertaining, it will quickly gentrify. I think a lot of people in DTES don’t need entertainment, they need jobs. They need housing.
- Jeffrey Ellis, cloudscapecomics.com: Jeffrey gave a very quick talk advertising a group of comic artists who were about to release (just released?) another comic book.
- Tom Williams, GiveMeaning: Tom told the story of how he used to be making big bucks in high finance, and thought he was happy until someone he had known before asked him a penetrating question. I don’t remember the question, but it was something along the lines of “Are you really happy?” or “Does your life have meaning?” and that made him realize he wasn’t happy. Tom quit his job and went looking for his purpose and couldn’t find it. He came back to Vancouver, found that guy, and said something along the lines of “You ruined my life with your question, how do I fix it?” The guy said, “Follow your passion.” Tom said, “How do I find my passion????” The guys said, “Follow your tears.” From that, Tom started a micro-charity site. (Think microlending, but microgiving instead.) People can create projects (e.g. “sponsor me for the Breast Cancer Walk”) that others can then donate small amounts to.
- I don’t mind giving people a little bit of money sometimes, but I do resent being on their mailing list forever and ever after. When he explained his site, it made me think of all the trees that have died in the service of trying to extract more money from me. 🙁
- His friend’s advice, “Follow your tears” has hung around with me since. I told my beloved husband that it probably meant that I had to go back to the US to try to fix the system. Unfortunately, I find activism really boring. 🙁
- Naomi Devine, uvic.commonenergy.org: I don’t have a strong memory of this talk. I think she was arguing for getting involved in local politics, especially green politics. I suspect that the talk didn’t register because it either trying to persuade me of something I already believe, or teaching me how to do something I already know.
- James Glave, glave.com: I have very weak memories of this talk also. I think again, he was trying to persuade me on something I’m already persuaded on.
- Colin Keddie, Buckeye Bullet: Colin gave kind of a hit-and-run talk about the Buckeye Bullet, a very very fast experimental car developed at Ohio State University and which runs on fuel cells.
- I would have liked to have heard more about how the car worked, the challenges that they faced, etc. However, he only had three minutes, and that’s not a lot of time.
- (Slightly off-topic: I got to see a talk on winning the DARPA challenge when I was at Google. It’s a great talk, I highly recommend it.)
- Joe Solomon, engagejoe.com: I don’t have any memories of this talk. Maybe I was getting tired then? Maybe I’m getting tired now?
- Dave Ng, biotech.ubc.ca: Dave’s talk was on umm science illiteracy.
- Dave gave a very engaging talk. He put up three questions, and had us talk to our neighbours to help us decide if they were true or false. All of them seemed to be designed to be so ridiculous that they couldn’t possibly be true. I happened to have read Science News for enough years, that I was very confident that the first two were true (which they were). The third was something about how 46% of Americans believe they are experts in the evolutionary history of a particular type of bird — again it looked like it couldn’t possibly be true. It was a bit of a fakeout: it turned out that 46% of Americans thought that the Genesis story was literally true.
- The audience participation was fun.
- David Young, 2ndglobe.com: David talked about Great Place/times and wondered why Vancouver couldn’t do that. He pointed out that Athens in Socrates’ time, Florence in Michelangelo’s time, Vienna in Beethoven’s time, the Revolutionary War-era US, and several other place/times had far fewer residents than Vancouver, so why can’t we do the same?
- I have thought about this, and maybe I read something about this elsewhere, but I believe there are a few factors that account for most of why the great place/times were great:
- Great wealth (which means lots of leisure time). Frequently this wealth came by exploiting some other people. The US Founding Fathers and Athenians had slaves, for example.
- Lack of entertainment options. We are less likely to do great things if The Simpsons is on.
- Lack of historical competition. Michelangelo showed up at a time when the Church was starting to be a bit freer in what it would tolerate in art. (Michelangelo’s David was the second nude male sculpture in like 500 years…)
- Technological advances. Shakespeare wasn’t competing with hundreds of years of other playwrights, he was competing with around 100 years of post-printing-press playwrights. The other playwrights and authors’ work didn’t get preserved. The French impressionists were able to go outside and paint because they were able to purchase tubes of paint that they could take with them and which didn’t dry too fast. (They also had competition from the camera for reproducing scenes absolutely faithfully, so needed to do something cameras couldn’t do.)
I also had an interesting time talking with Ray-last-name-unknown, who I met at some event a few months ago and who I’d spoken to at length at Third Tuesday just a few nights before. We walked back to downtown together and didn’t have any dead spots in the conversation.
Permalink
06.12.07
Posted in programmer productivity, review at 4:08 pm by ducky
Some basic determinants of computer programming productivity by Earl Chrysler (1978) measured the (self-reported) time it took professional programmers to complete COBOL code in the course of their work and looked for correlations.
He correlated the time it took with characteristics of the program and, not surprisingly, found a bunch of things that correlated with the number of hours that it took: the number of files, number of records, number of fields, number of output files, number of output records, number of output fields, mathematical operations, control breaks, and the number of output fields without corresponding input fields. This is not surprising, but it is rather handy to have had someone do this.
He then looked at various features of the programmers themselves to see what correlated. He found that experience, experience at that company, experience in programming business applications, experience with COBOL, years of education, and age all correlated, with age correlating the most strongly. (The older, the faster.) This was surprising. I’ve seen a number of other academic studies that seemed to show no effect of age or experience. The Vessey paper and the Schenk paper (which I will blog about someday, really!), for example, have some “experts” with very little experience and some “novices” with lots of experience.
The academic studies, however, tend to have a bunch of people getting timed doing the same small task. Maybe the people who are fastest in small tasks are the ones who don’t spend much time trying to understand the code — which might work for small tasks but be a less successful strategy in a long-term work environment.
Or the paper is just messed up. Or all the other papers are messed up.
Gotta love research.
Update: Turley and Bieman in Competencies of Exceptional and Non-Exceptional Software Engineers (1993) also say that experience is the only biographical predictor of performance. (“Exceptional engineers are more likely than non-exceptional engineers to maintain a ‘big picture’, have a bias for action, be driven by a sense of mission, exhibit and articulate strong convictions, play a pro-active role with management, and help other engineers.”)
Update update: Wolverton in The cost of developing large-scale software found that the experience of the programmer didn’t predict the routine unit cost. It looks like he didn’t control for how complex the code written was.
Permalink
06.05.07
Posted in programmer productivity, review at 4:07 pm by ducky
I really wanted to like Expertise in Debugging Computer Programs: a Process Analysis by Iris Vessey (Systems, Man and Cybernetics, IEEE Transactions on, Vol. 16, No. 5. (1986), pp. 621-637.) Van Mayrhauser and Vans said in Program Comprehension During Software Maintenance and Evolution indicated that Vessey had shown that experts use a breadth-first approach more than novices.
I was a little puzzled, though, because Schenk et al, in Differences between novice and expert systems analysts: what do we know and what do we do? cited the exact same paper, but said that novices use a breadth-first approach more than experts! Clearly, they both couldn’t be right, but I was putting my money on Schenk just being wrong.
It also looked like the Vessey paper was going to be a good paper just in general, that it would tell me lots of good things about programmer productivity.
Well, it turns out that the Vessey paper is flawed. She studied sixteen programmers, and asked them debug a relatively simple program in the common language of the time — COBOL. (The paper was written in 1985.) It is not at all clear how they interacted with the code; I have a hunch that they were handed printouts of the code. It also isn’t completely clear what the task termination looked like, but the paper says at one point “when told they were not correct”, so it sounds like they said to Vessey “Okay, the problem is here” and Vessey either stopped the study or told them “no, keep trying”.
Vessey classified the programmers as expert and novice based on the number of times they did certain things while working on the task. (Side note: in the literature that I’ve been reading, “novice” and “expert” have nothing to do with how much experience the subjects have. They are euphemisms for “unskilled” and “skilled” or perhaps “bad” and “good”.)
She didn’t normalize by how long they spent to finish the task, she just looked at the count of how many times they did X. There were three different measures for X: how often did the subject switch what high-level debugging task they were doing (e.g. “formulate hypothesis” or “amend error”); start over; change where in the program they were looking.
She then noted that the experts finished much faster than the novices. Um. She didn’t seem to notice that the that the count of the number of times that you do X during the course of a task is going to correlate strongly with how much time you spend on the task. So basically, I think she found that people who finish faster, finish faster.
She also noted that the expert/novice classification was a perfect predictor of whether the subjects made any errors or not. Um, the time they took to finish was strongly correlated with whether they made any errors or not. If the made an error, they had to try again.
Vessey said that 15/16 experts could be classified by a combination of two factors: whether they used a breadth-first search (BFS) for a solution or a depth-first search (DFS) whether they used systems thinking or not However, you don’t need both of the tests; just the systems-thinking test accurately predicts 15/16. All eight of the experts always used BFS and systems-thinking, but half of the novices also used BFS, while only one of the novices used systems-thinking.
Unfortunately, Vessey didn’t do a particularly good job of explaining what she meant by “system thinking” or how she measured it.
Vessey also cited literature that indicated that the amount of knowledge in programmer’s long-term memory affected how well they could debug. In particular, she said that the chunking ability was important. (Chunking is a way to increase human memory capacity by re-encoding the data to match structures that are already in long-term memory, so that you merely have to store a “pointer” to the representation of the aggregate item in memory, instead of needing to remember a bunch of individual things. For example, if I ask you to remember the letters C, A, T, A, S, T, R, O, P, H, and E, you will probably just make a “pointer” to the word “catastrophe” in your mind. If, on the other hand, I ask you to remember the letters S, I, T, O, W, A, J, C, L, B, and M, that will probably be much more difficult fo you.)
Vessey says that higher chunking ability will manifest itself in smoother debugging, which she then says will be shown by the “count of X” measures as described above, but doesn’t justify that assertion. She frequently conflates “chunking ability” with the count of X, as if she had fully proven it. I don’t think she did, so her conclusions about chunking ability are off-base.
One thing that the paper notes is that in general, the novices tended to be more rigid and inflexible about their hypotheses. If they came up with a hypothesis, they stuck with it for too long. (There were also two novices who didn’t generate hypotheses, and basically just kept trying things somewhat at random.) This is consistent with what I’ve seen in other papers.
Permalink
04.24.07
Posted in programmer productivity, review at 2:12 pm by ducky
I’m reading A framework and methodology for studying the causes of software errors in programming systems by Ko and Myers that classifies the causes of software errors, and there is a diagram (Figure 4) that I’m really taken with. They talk about there being three different kinds of breakdowns: skill breakdowns (what I think of as “unconscious” errors, like typos), rule breakdowns (using the wrong approach/rule, perhaps because of a faulty assumption or understanding), and knowledge breakdowns (which usually reflect limitations of mental abilities like inability to hold all the problem space in human memory at one time).
Leaving out the breakdowns, the diagram roughly looks like this:
| Specification activities |
| Action |
Interface |
Information |
| Create |
Docs |
Requirement specifications |
| Understand |
Diagrams |
Design specifications |
| Modify |
Co-workers |
|
| Implementation activities |
| Action |
Interface |
Information |
| Explore |
Docs |
Existing architecture |
| Design |
Diagrams |
Code libraries |
| Reuse |
Online help |
Code |
| Understand |
Editor |
|
| Create |
|
|
| Modify |
|
|
| Runtime (testing and debugging) activities |
| Action |
Interface |
Information |
| Explore |
Debugger |
Machine behavior |
| Understand |
Output devices |
Program behavior/td> |
| Reuse |
Online help |
Code |
I’m a bit fuzzy on what exactly the reuse “action” is, and how “explore” and “understand” are different, but in general, it seems like a good way to describe programming difficulties. I can easily imagine using this taxonomy when looking at my user study.
Permalink
02.16.07
Posted in programmer productivity, review at 5:12 pm by ducky
I got started on looking at productivity variations again and just couldn’t stop. I found Programmer performance and the effects of the workplace by DeMarco and Lister (yes, the authors of Peopleware). The paper is well worth a read.
In their study, they had 83 pairs of professional programmers work all on the same well-specified programming problem using their normal language tools in their normal office environment. Each pair was two people from the same company, but they were not supposed to work together.
- They found a strong correlation between the two halves of a company pair, which may be in part from
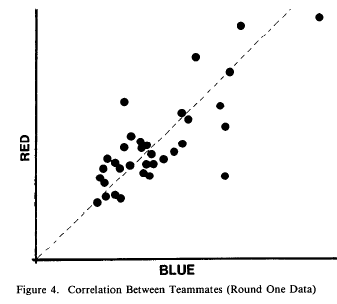
- a pretty stunning correlation between the office environment and productivity
- (or perhaps due to different companies having radically different tools/libraries/languages/training/procedures, which they didn’t discuss)
- The average time-to-complete was about twice the fastest time-to-complete.
- Cobol programmers as a group took much longer to finish than the other programmers. (Insert your favorite Cobol joke here.)
Over and over, I keep seeing that the median time to complete a single task is on the order of 2x to 4x times the fastest, not 100x. This study seems to imply that a great deal of that difference is due not to the individual’s inherent capabilities, but rather the environment where they work.
Permalink
Posted in programmer productivity, review at 4:17 pm by ducky
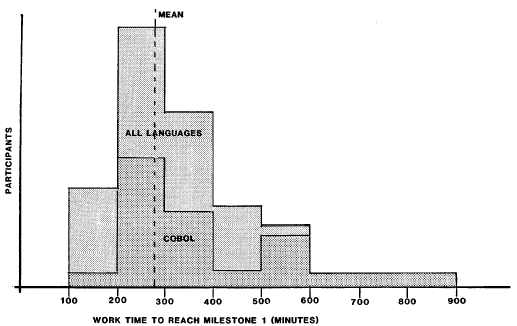
To reiterate, there’s a paper by Sackman et al from 1966 that people have seized upon to show a huge variation in programmer productivity, a paper by Dickey in 1981 that refuted Sackman pretty convincingly, and an article by Curtis in the same issue as Dickey’s. I didn’t talk much about the Dickey paper, but Tony Bowden has a good blog posting on the Dickey paper, where Dickey reports on a more reasonable interpretation of numbers from the Sackman’s data.
(Basically, Sackman compared the time it took to complete a task using a batch system against the time it took using a timeshare system. This was interesting in 1966 when they were trying to quantify the benefit of timeshare systems, but it’s not good to look at those numbers and say, “Ah, see, there is a huge variation in programmers!”)
Because I like making pretty histograms, here are the Sackman numbers via Dickey via Bowden — the way they ought to be interpreted. These show the time to complete for two tasks, the “Algebra” task and the “Maze” task.


The small sample size hurts, but (as in the Curtis data and the Ko data) I don’t see an order of magnitude difference in completion speed.
Permalink
02.15.07
Posted in programmer productivity, review at 6:18 pm by ducky
(See my previous programmer productivity article for some context.)
Martin Robillard did a study in conjunction with my advisor. In it, he had five programmers work on a relatively complex task for two hours. Two of the programmers finished in a little over an hour, one finished in 114 minutes, and two did not finish in two hours:

Robillard carefully looked at five subtasks that were part of doing the main task; there was a very sharp distinction between the three who finished and the two who did not. The two who didn’t finish only got one of the subtasks “right”. S for “Success” means everything worked. I for “Inelegant” means it worked but was kind of kludgy. B for “Buggy” means that there were cases where it didn’t work; U for “Unworkable” means that it usually didn’t work; NA for “Not Attempted” means they didn’t even try to do that subtask.
| Coder ID |
Time to finish |
Check box |
Disabling |
Deletion |
Recovery |
State reset |
Years exper. |
| #3 |
72 min |
S! |
S! |
S! |
S! |
S! |
5 |
| #2 |
62 min |
S! |
S! |
S! |
S! |
B |
3 |
| #4 |
114 min |
I |
S! |
B |
S! |
B |
5 |
| #1 |
125 min (timed out) |
S! |
U |
U |
U |
NA |
1 |
| #5 |
120 min (timed out) |
S! |
U |
U |
NA |
NA |
1 |
Because coder #1 and coder #5 timed out, I don’t know how much of a conclusion I can draw from this data about what the range of time taken is. From this small sample size, it does look like experience matters.
This study did have some interesting observations:
- Everyone had to spend an hour looking at the code before they started making changes. Some spent this exploration period writing down what they were going to change, then followed that script during the coding phase. The ones who did were more successful than the ones who didn’t.
- The more successful coders (#2 and #3) spread their changes around as appropriate. The others tried to make all of the changes in one place.
- The more successful coders looked at more methods, and they were more directed about which ones they looked at. The second column in the table below is a ratio of the number of methods that they looked at via cross-references and keyword searching over the total number of methods that they looked at. The less-successful coders found their methods more frequently by scrolling, browsing, and returning to an already-open window.
| Coder ID |
Number of methods examined |
intent-driven:total ratio |
Time to finish |
| #3 |
34 |
31.7% |
72 min |
| #2 |
27.5 |
23.3% |
62 min |
| #4 |
27.5 |
30.8% |
114 min |
| #1 |
8.5 |
2.0% |
125 min (timed out) |
| #5 |
17.5 |
10.7% |
120 min (timed out) |
- From limited data, they conclude that skimming the source isn’t very useful — that if you don’t know what you are looking for, you won’t notice it when it passes your eyeballs.
Permalink
12.15.06
Posted in programmer productivity, review at 4:58 pm by ducky
I found another paper that has some data on variability of programmers’ productivity, and again it shows that the differences between programmers isn’t as big as the “common wisdom” made me think.
In An Exploratory Study of How Developers Seek, Relate, and Collect Relevant Information during Software Maintenance Tasks, Andrew Ko et al report on the times that ten experienced programmers spent on five (relatively simple tasks). They give the average time spent as well as the standard deviation, and — like the Curtis results I mentioned before. (Note, however, that I believe Ko et al include programmers who didn’t finish in the allotted time. This will make the average lower than it would be if they waited for people to finish, and make the standard deviation appear smaller than it really is.)
| Task name |
Average time |
Standard deviation |
std dev / avg |
| Thickness |
17 |
8 |
47% |
| Yellow |
10 |
8 |
80% |
| Undo |
6 |
5 |
83% |
| Line |
22 |
12 |
55% |
| Scroll |
64 |
55 |
76% |
These numbers are the same order of magnitude as the Curtis numbers (which were 53% and 87% for the two tasks).
Ko et al don’t break out the time spent per-person, but they do break out actions per person. (They counted actions by going through screen-video-captures, ugh, tedious!) While this won’t be an exact reflection of time, it presumably is related: I would be really surprised if 12 actions took longer than 208 actions.
I’ve plotted the number of actions per task in a bar graph, with each color representing a different coder. The y-axis shows the time spent on each task, with negative numbers if they didn’t successfully complete the task. (Click on the image to see a wider version.)
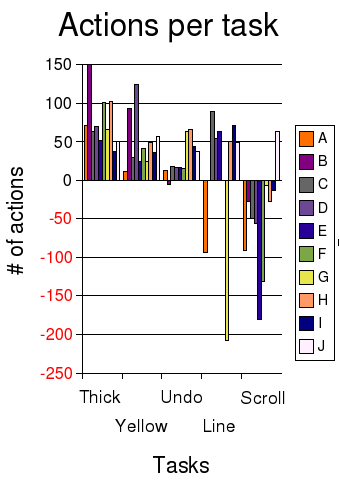
Looking at the action results closely, I was struck by the impossibility of ranking the programmers.
- Coder J (white) was the only one who finished the SCROLL task (and so the only one who finished all five), so you’d think that J was really hot stuff. However, if you look at J’s performance on other tasks, it was solid but not overwhelmingly fast.
- Coder A (orange) was really fast on YELLOW and UNDO, so maybe Coder A is hot stuff. However, Coder A spun his or her wheels badly on the LINE task and never finished.
- Coder G (yellow) got badly badly stuck on LINE as well, but did a very credible job on most of the other tasks, and it looks like he or she knew enough to not waste too much time on SCROLL.
- Coder B (light purple) spent a lot of actions on THICKNESS and YELLOW, and didn’t finish UNDO or SCROLL, but B got LINE, while A didn’t.
One thing that is very clear is that there is regression to the mean, i.e. the variability on all the tasks collectively is smaller than the variability on just one task. People seem to get stuck on some things and do well on others, and it’s kind of random which ones they do well/poorly on. If you look the coders who all finished THICKNESS, YELLOW, UNDO, and SCROLL, the spread is higher on the individual tests than the aggregate:
- The standard deviation of the number of actions taken divided by the average number of actions is 36%, 69%, 60%, and 25%, respectively.
- If you look at the number of actions each developer takes to do *all* tasks, however, then the standard deviation is only 21% of the average.
- The most actions taken (“slowest”) divided by the least actions (“fastest”) is 37%, 20%, 26%, and 54% respectively.
- The overall “fastest” coder did 59% as many actions as the “slowest” overall coder.
It also seemed like there was more of a difference between the median coder and the bottom than between the median and the top. This isn’t surprising: there are limits to how quickly you can solve a problem, but no limits to how slowly you can do something.
What I take from this is that when making hiring decisions, it is not as important to get the top 1% of programmers as it is to avoid getting the bottom 50%. When managing people, it is really important to create a culture where people will give to and get help from each other to minimize the time that people are stuck.
Permalink

