12.19.06
Posted in University life at 10:46 am by ducky
This morning I had a actual, genuine, real, honest-to-goodness I-forgot-to-take-an-exam nightmare — and I’m not even taking any classes this term.
My father said that he knew he was a grownup when he had a nightmare that he forgot to give an exam; I knew that I was a grownup when I had a dream that I had forgotten an exam and, even in the dream, was completely not concerned about it. I believe that was my first exam dream; today’s was definitely the only one since.
In this morning’s dream, a whole cavalcade of things were causing anxiety: not only had I forgotten to take my Econ class (in reality, I haven’t had an Econ class in my life), I had lost my wedding ring, and I needed to pee and fell in the toilet! (I’d also forgotten to start my History of Marriage term paper, but I wasn’t very concerned about that even in the dream because I could write that paper in my sleep, so to speak.)
My husband says that he gets nightmares when he gets too warm — that it’s the brain’s way of making you take off a blanket — but I wasn’t overly warm. I needed to pee, but it wasn’t urgent. It was 9:45 AM: Jim had gotten up at 6:30 AM to go flying, which messed up my sleep cycle and he turned off the alarm clock.
I think the dream was just my brain’s way of making me get my indolent posterior out of bed.
Permalink
12.17.06
Posted in programmer productivity at 10:16 pm by ducky
What factors go into programmer productivity? I’ve been thinking about that a lot lately.
My recent reflections on the Curtis results and reflections on the Ko et al results of experiments of programmer productivity have focused on one narrow slice, what I call “hands-on-keyboard”. Hands-on-keyboard productivity is measured by how fast someone who is given a small, well-defined task can do that task. As I mentioned in those two blog posts, it is hard to measure even that simple thing.
In the wild, there are a huge number of factors that don’t bear on the types of experiments that Curtis and Ko et al did:
- How much time does the coder spend actually working? If Jane buries her nose in a keyboard for 60 hours per week, while Fred is only at work on an average of 38 hours every week, plus spends 15 hours goofing off away from his desk (talking at the water cooler/playing pool/reading on the john), 15 hours reading email, and 8 hours surfing the Web, then it is highly likely that Jane will be more productive than Fred.
- How much work time does the coder spend on writing code? If Bill’s company has a lot of bureaucratic overhead, and/or he writes a lot of documentation, serves on the Emergency Response Team, gathers requirements from the customers, explains the limitations to marketing, etc, then even if Bill works 60 hours per week, he’s probably not going to be as productive as nose-in-keyboard Jane.
- How much coding time does the coder spend on the right code for the project? If Joe spends a lot of time to make the least-often-run method run 10% faster, then that will be less useful than if he spent the time making the most-often-run method run 10% faster. Note that inefficiencies can come either from Joe or his management. Management might give direct orders to work on something useless; Joe might disobey sensible orders from management.
- How much time does the coder spend on the right project? If George’s project gets cancelled and Jane’s doesn’t, then Jane’s contribution will be more valuable.
- How well does the coder design? The problems that Curtis and Ko et al gave were all quite small and built upon a pre-existing code base. While there are many tasks which only require modifying an existing code base, there are very few programming jobs that don’t demand any design. Being able to map out a good design makes the implementation much, much easier.
- What damage does the coder leave in his/her wake? If Brian aggravates people so much that Brian’s boss has to spend a lot of time on damage control, while Jane is totally inoffensive, then Jane will probably be more valuable. Brian has a negative productivity penalty that has to get paid along with the positive work that he does.
All of these things are very important — perhaps more important than the hands-on-keyboard productivity. I am starting to lose faith that differences in programmer productivity can be measured in a meaningful way. 🙁
Permalink
12.15.06
Posted in Canadian life at 6:00 pm by ducky
My experiences with Canadian bureaucracy have been surprisingly pleasant. For example:
- When I went to apply for my SIN ID (a tax ID number, equivalent to the US Social Security number), it took me twenty minutes from the time I got in the door to the time I walked out.
- Seven relatives and I were on Pender Island when storms knocked out power and heat at the house we were renting for the weekend. I called BC Ferries to find out if Pender Island’s ferry terminal had a warm place to wait, if the ferries were running, if we could leave early, etc. I immediately got a real human being who happily gave me what information she had and the direct phone number to the Pender terminal, and wished me luck getting home.
- Jim phoned the BC tax office to ask a question about setting up his consulting business. He got one level of phonebot menu before being sent to a human. The human picked up in two rings, answered his question, and wished him luck in his venture.
In addition to being very pleasant to deal with, the Canadian bureaucracies seem much more flexible than U.S. ones. It seems that in the U.S., There Are Rules, and the individual agents have no discretion. In Canada, it seems like the agents have much more discretion to be reasonable.
This is probably due in part to a much smaller population, meaning fewer levels of bureaucracy. I suspect that it’s also due to smaller socioeconomic stratification. As Larissa Tieden’s research explains, humans think that low-status people do bad things. This means that if there are fewer low-status people dealing with the bureaucracy, then there will be less suspicion about them trying to “take advantage of the system”.
I’ve often thought about how income discrepancies hurt even the wealthy: they have to worry more about crime, for example. I hadn’t ever thought about how status discrepancies might make bureaucracy more annoying.
(Note that I have the impression that people think that European bureaucracies are worse than U.S. bureaucracies; perhaps this is due to greater emphasis on social class?)
Permalink
Posted in programmer productivity, review at 4:58 pm by ducky
I found another paper that has some data on variability of programmers’ productivity, and again it shows that the differences between programmers isn’t as big as the “common wisdom” made me think.
In An Exploratory Study of How Developers Seek, Relate, and Collect Relevant Information during Software Maintenance Tasks, Andrew Ko et al report on the times that ten experienced programmers spent on five (relatively simple tasks). They give the average time spent as well as the standard deviation, and — like the Curtis results I mentioned before. (Note, however, that I believe Ko et al include programmers who didn’t finish in the allotted time. This will make the average lower than it would be if they waited for people to finish, and make the standard deviation appear smaller than it really is.)
| Task name |
Average time |
Standard deviation |
std dev / avg |
| Thickness |
17 |
8 |
47% |
| Yellow |
10 |
8 |
80% |
| Undo |
6 |
5 |
83% |
| Line |
22 |
12 |
55% |
| Scroll |
64 |
55 |
76% |
These numbers are the same order of magnitude as the Curtis numbers (which were 53% and 87% for the two tasks).
Ko et al don’t break out the time spent per-person, but they do break out actions per person. (They counted actions by going through screen-video-captures, ugh, tedious!) While this won’t be an exact reflection of time, it presumably is related: I would be really surprised if 12 actions took longer than 208 actions.
I’ve plotted the number of actions per task in a bar graph, with each color representing a different coder. The y-axis shows the time spent on each task, with negative numbers if they didn’t successfully complete the task. (Click on the image to see a wider version.)
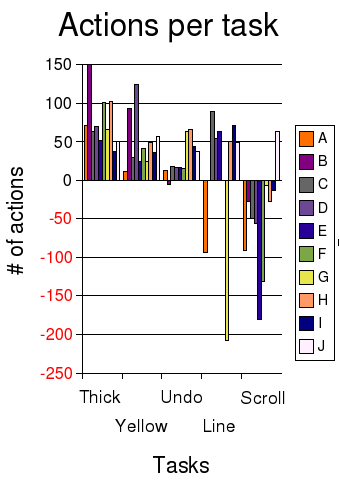
Looking at the action results closely, I was struck by the impossibility of ranking the programmers.
- Coder J (white) was the only one who finished the SCROLL task (and so the only one who finished all five), so you’d think that J was really hot stuff. However, if you look at J’s performance on other tasks, it was solid but not overwhelmingly fast.
- Coder A (orange) was really fast on YELLOW and UNDO, so maybe Coder A is hot stuff. However, Coder A spun his or her wheels badly on the LINE task and never finished.
- Coder G (yellow) got badly badly stuck on LINE as well, but did a very credible job on most of the other tasks, and it looks like he or she knew enough to not waste too much time on SCROLL.
- Coder B (light purple) spent a lot of actions on THICKNESS and YELLOW, and didn’t finish UNDO or SCROLL, but B got LINE, while A didn’t.
One thing that is very clear is that there is regression to the mean, i.e. the variability on all the tasks collectively is smaller than the variability on just one task. People seem to get stuck on some things and do well on others, and it’s kind of random which ones they do well/poorly on. If you look the coders who all finished THICKNESS, YELLOW, UNDO, and SCROLL, the spread is higher on the individual tests than the aggregate:
- The standard deviation of the number of actions taken divided by the average number of actions is 36%, 69%, 60%, and 25%, respectively.
- If you look at the number of actions each developer takes to do *all* tasks, however, then the standard deviation is only 21% of the average.
- The most actions taken (“slowest”) divided by the least actions (“fastest”) is 37%, 20%, 26%, and 54% respectively.
- The overall “fastest” coder did 59% as many actions as the “slowest” overall coder.
It also seemed like there was more of a difference between the median coder and the bottom than between the median and the top. This isn’t surprising: there are limits to how quickly you can solve a problem, but no limits to how slowly you can do something.
What I take from this is that when making hiring decisions, it is not as important to get the top 1% of programmers as it is to avoid getting the bottom 50%. When managing people, it is really important to create a culture where people will give to and get help from each other to minimize the time that people are stuck.
Permalink
Posted in Technology trends at 10:24 am by ducky
Google Maps now has multipoint routing! For example, see this map from LA to Chicago to Minneapolis to Miami to Houston.
I didn’t work on multipoint routing, but my cubemate did. 🙂
Permalink
12.07.06
Posted in programmer productivity at 9:39 pm by ducky
I’ve heard a few people say that the most productive programmers are about 100x more productive than the least, but that didn’t seem to ring true to me. The only times that I’ve seen someone taking five months to produce as much as someone else could do in one day, it was a management problem. The low-productivity person was either goofing off or (more commonly) they were working on the wrong thing.
In Joelonsoftware, Joel reports (using data from Professor Stanley Eisenstat at Yale) that he sees about a 3x or 4x difference in the time students put into an assignment (with no effect of grades). However — and this is a big “however” — Prof. Eisenstat depends upon self-reporting from the students. Self-reporting is notoriously inacurate.
I have found it surprisingly hard to find good academic literature that measures productivity. I finally found a 1966 study by Sackman that showed a 28x difference. That number apparently got widely circulated, despite some sloppiness in its methods (as refuted by Dickey in 1981). A response to the concern by Curtis (1981) gave data that showed of about 8x and 13x min:max for two problems if and only if you tossed out one outlier who got stuck and didn’t finish that problem, timing out instead. Keeping the outlier, the 13x changed to 22x.
The outlier made me realize that the difference between the “best” programmer and the “worst” programmer is the wrong measure. You can make that number arbitrarily large by finding the right person to compare against. For example, I will be infinitely more productive than an infant. I will be infinitely more productive than someone who sleeps at his/her desk for their entire workday every day.
I would be far more interested in the standard deviation, or perhaps the productivity difference between the median and the top performer. What is the performance hit if I hire people within two standard deviations of the mean instead of trying for the ones who are better than two sigma above the mean? (This should looked at in conjunction with the cost hit of hiring the absolute best.)
This graph shows the time that it took to complete some tasks, and the number of people who took that long. (One person took between 65 and 70 minutes to complete Task 2, for example.)

Using Curtis’ data, I get that the median coder takes 2x or 3x the time that the top coder does for each of Curtis’ two tasks. (It’s not exact because the data was bucketed into five-minute intervals.) Interestingly, this is the same order of magnitude that Prof. Eisenstat found.
Note, however, that Curtis gives measures for one task. Because of regression to the mean, the variation is likely to decrease if you look at a lot of tasks. (Curtis even mentions that the outlier on Task #2 did fine on other tasks.)
The shapes of the curves are interesting: they are skewed to the left, which makes sense: there are limits to how much faster you can get, but not to how much slower you can get. They are also bimodal. This is more intriguing and mysterious, especially since Saeed and Bornat found that grades in intro CS classes are bimodal.
While this data comes from 1981, it’s the best I could find so far. (Please tell me if you have better data!) It’s distressing that we don’t have lots of good data on this — it seems like such fundamental data! However, it is really hard to do good studies like this. Ideally, you’d want a large number of programmers to all work on the same large number of complex problems. Unfortunately, it’s very difficult to get a large number of programmers to spend a large number of hours on non-useful problems.
The big message that I take from this data for my personal use is don’t get stuck. That’s easier said than done, I know. But look at it this way: if I learn new tricks for squeezing out incremental gains — like memorizing all the keyboard shortcuts — that isn’t going to help me nearly as much as not getting stuck. Keyboard shortcuts might give take me from 10 minutes to 9 minutes, but getting stuck can easily take me from 10 minutes to 100 minutes.
Now all I have to do is figure out how to not get stuck.
Permalink

