Why are there so many? Surely, you say, we don’t need so many candidates. Why did so many companies try? Why don’t most of them quit now. Why don’t the losers just manufacture the winners’ vaccines?
There are several reasons why there are so many.
There are nearly 8 billion people out there. That huge market means a huge opportunity to make money, so many people wanted to invest.
There are lots of different market segments out there, and not all vaccines are appropriate for all markets. For example:
Wealthy countries with good infrastructure are able to cope with the refrigeration demands of the mRNA vaccines, while poor countries might not be able to.
Wealthy countries can buy expensive vaccines, while poor countries might not be able to afford it.
Countries have a financial incentive to fund domestic development of vaccines. COVID-19 costs a huge, huge amount in lives, money, and social well-being, for every single day that the pandemic continues. Compared to being in a pandemic longer, a vaccine development program is cheap.
Countries have domestic security reasons to develop their own vaccines:
Countries would rather not have to inject their citizens with liquids coming from their political rivals. For example, Taiwan might not want not trust vaccines from China.
There are (IMHO legitimate) concerns that other countries might slap export controls on vaccines developed in their home countries, insisting that those vaccines go to their own citizens first. Countries have no control over when they can have access to foreign vaccines, but might be able to exert some control over domestic providers’ priority and sequencing choices.
Players — both countries and companies — have an incentive to invest in vaccine technology to ensure long-term competitiveness, especially for mRNA vaccines. The mRNA vaccines are so good that being able to make them domestically is a huge strength, both in terms of being able to make your citizens healthier in the future and in terms of increasing your country’s economic might.
As for the question of why the losers don’t just manufacture the “winners'” vaccines, in addition to #5 above:
The “losers” might not have accepted yet that they have “lost”. Even if the pandemic eases in the developed countries in the next year, there’s still going to be billions of people who still need the vaccine. So even if the “loser” vaccine doesn’t get to market for a year, there’s still a lot of time to make money on the vaccine after that.
The “winners” might not feel comfortable licensing their manufacturing technology to their rivals. Why should Moderna show Providence Therapeutics how to make mRNA vaccines, when Providence might turn into a competitor later on?
It would make more sense for the “winners” to flat-out buy their competitors. The winners presumably are making money right now, so they ought to be able to afford it.
The “winners” are busy right now. They are making (and selling!) vaccines as fast as they can at the moment. Technology transfer deals — or outright purchases — take time and attention, and companies like Moderna probably do not have any attention to spare at the moment. Look for deals in a year or two. (Right now, Pfizer is doing an internal upgrade to its factory to boost production, causing a short-term drop in supply, causing people to totally lose their collective shit enormous consternation among their customers.)
There is a lot of nervousness right now about new strains of the SARS-CoV-2 virus. There is now very good evidence that the B.1.1.7 (“UK”) strain is more transmissible than the original strain (which I will call the “Wuhan” strain because I haven’t seen anyone give it a name). There are also strains out of South Africa and Brazil which have similar mutations and are similarly worrying.
So I have been wondering how fast Moderna and Pfizer/BioNTech could tweak their strains to produce vaccines targeting the UK strain instead of the Wuhan strain. That has not been entirely straightforward to figure out, but I think I have finally pieced it together from reading, mostly from this and this.
The things that need to be done include:
Get the DNA sequence of the new strain’s spike protein. That’s something which comes from outside the company. (Zero additional time.)
Modify the sequence slightly in completely predictable ways: add a start block on, add an end block, convert all the thymine with 1-methyl-3’-pseudouridylyl, translate some bases into equivalent sequences to get a higher proportion of cytosine and guanine, etc. (See Reverse Engineering the source code of the BioNTech/Pfizer SARS-CoV-2 Vaccine for more on these algorithmic modifications.) (Educated guess: probably fifteen minutes of additional time, not even worth counting.)
Modify the sequence slightly to improve manufacturability. This will be a proprietary step that the company will do. Given how small the physical changes are between the Wuhan strain and the UK strain, I suspect that this step will not take long, and possibly could be skipped. (Guess: 0-1 days.)
Convert the text sequence into physical DNA, the “template DNA”. This is a completely straightforward, common process, but I don’t know how long it takes to get the amount of DNA needed. (Guess: 1-4 days)
Verify that you got the right DNA, I assume using a PCR test. (6 hours, 0.25 days)
After this point, all the rest of the production steps are exactly the same as are already being done for the Wuhan strain. If I were Pfizer or Moderna, I would already have done the previous steps for all of the scary variant strains and have a bunch of DNA on ice, ready to ship out if the green light was given. So it might in fact be zero additional days. (2-6 weeks, 6 weeks)
Addendum 2021-03-02: This article says that finish & fill — testing, getting the serum into the bottles, and labelling — take five weeks.
I have not heard of any official floating the idea of modifying the vaccine, probably because it looks like the Wuhan vaccine will be good enough against the UK strain. (Addendum: the B.1.351 is a different matter.) However, if there started to be rumbling about how the vaccine should be changed, if I were Pfizer or Moderna, I would actually go through all the steps to make enough doses of the UK vaccine for testing if need be.
It might be the first time we do it, we’ll check an immunogenicity study. But it’s not going to have to be another 30,000 patient clinical trial. Those immunogenicity studies are usually 400 patients, just to make sure that we have the right check of what’s coming out. And even that may not be necessary after we check at the first one or two times. So I think we’ll have a way of evolving here with these.
If I understand correctly, immunogenicity studies are tests of the blood which check to make sure that the vaccine causes the desired immune response.
This would mean that the the company would vaccinate volunteers — apparently about 400 — give them enough time for their immune system to react
Recruit test participants. Hopefully they would have volunteers ready to go. (Zero additional days.)
Wait for the test participants’ immune systems to react to the vaccines. (14 days.)
At this point, the test participants’ blood could be tested to see if it mounts the desired immune response. One might think they could stop there, but regulatory agencies probably would want to check after the second dose. Moderna ran their first trials with a 21 day delay; Pfizer did a 28 day delay. (7 or 14 more days) Addendum 2021-03-04: These new vaccines are being positioned as boosters, which means there would not be a second dose.
Give all the volunteers their second dose. (1 day)
Wait for the volunteers’ immune systems to react to the vaccines. (14 days.)
Take blood samples from the test participants. (1 day)
Test blood to see if it mounts the desired immune response. (Guess: 2 days)
Write up report. I think this wouldn’t take long because they could copy and paste a lot from the Wuhan vaccine’s report. (Guess: 2-7 days.)
At this point, it would go to the regulatory bodies.
Add that all up, and it comes out to about 7-8 weeks from finishing the vaccine production to the data delivered to regulators, 3-4 weeks if they only require one dose.
The regulators would need to evaluate the data. Different regulators take different lengths of times, but the Pfizer vaccine took about three weeks from the application to approval by the US Food and Drug administration, and about the same amount of time for Health Canada to approve it. A new strain would have far less data to pore through, so I would guess it would be only a week or so. (Guess: 1-3 weeks)Addendum 2021-03-04: I’m now thinking 1 week is probably too optimistic. Say 1-3 weeks.
In summary, my best guess is 4-6 weeks to manufacture the new vaccine, 7-8 weeks to do clinical trials, and 1-3 weeks for approval, or a total of 12-18 weeks.
Addendum 2021-02-06: According to a Washington Post article on 2021-01-25, Moderna has started working on a vaccine for the P.1 variant.
The scientific and pharmaceutical race to keep coronavirus vaccines ahead of new virus variants escalated Monday, even as a highly transmissible variant first detected in people who had recently traveled to Brazil was discovered in Minnesota.
Moderna, the maker of one of the two authorized coronavirus vaccines in the United States, announced it would develop and test a new vaccine tailored to block a similar mutation-riddled virus variant in case an updated shot becomes necessary.
Addendum 2021-02-07: I forgot that the delay between the first and second dose is not 14 days, it’s 21 (for Moderna) and 28 (for Pfizer). I have adjusted accordingly.
A prime inventor of the technology behind mRNA vaccines, Drew Weissman, of the University of Pennsylvania, said he has been told by the leader of BioNTech that it could take as little as six weeks to formulate a new mRNA payload and manufacture it to target a variant. Pfizer chief executive Albert Bourla told investors earlier this month that he anticipates that a variant-specific vaccine could be approved in 100 days, including clinical testing and regulatory reviews.
Addendum 2021-02-25 from an article dated 2021-02-22: the US FDA has released guidelines on what testing vaccines against variant strains will need to do. They need to vaccinate volunteers with the variant vaccine, and look at the blood to see how big of a response to the virus variants the volunteers’ blood makes. If the response is comparable to the one from the Classic vaccines, it’s a go.Addendum 2021-03-04: There’s a consortium of European non-EU countries which says the same basic thing about approving vaccines against new strains.
However, I am proud of the moon landing. Not personally, but as a human. I am incredibly proud that we — collectively, over the centuries — managed to land on another celestial body.
The moon landing is a great example of this. To get to the moon, we had to build upon many technological achievements. We humans invented writing and governments and paper and books and lending libraries and addition and subtraction and exponents and the zero and protractors and slide rules and furnaces and tin snips and fireworks and rockets and tubes and space suits and we did it! Us humans!
I am also proud, as a human being, of mRNA vaccines.
Not at first — I was a little nervous about the mRNA vaccines when they first got approved for use against COVID-19. The mRNA vaccine was a very new technology, and there was a huge amount of pressure. Did corners get cut, sacrificing safety for speed?
But after reading a bit about it (especially this explanation), I was in absolute awe. The mRNA vaccines are sort of like “pre-vaccines”, which convince our own bodies to make the things we want our bodies to recognize and destroy. Instead of injecting us with millions of SARS-CoV-2 spike proteins, we get injected with instructions for our cells to make bazillions of spike proteins. This makes the mRNA vaccines 95% effective against the SARS-CoV-2 virus.
The mRNA vaccines are so beautiful (and effective) that they make all other vaccines now look primitive to me, like clumsy bumblings of extremely lucky ignoramuses. (“How did they ever work???”, I marvel.)
We humans — collectively, over the centuries — managed to figure out chemistry and anatomy and microscopes and cells and X-Rays and DNA and stop codons and antibodies and sequencing and ribosomes and introns and synthesis and how to do randomized clinical trials lipid nanoparticles and proline substitution and we did it!
After waiting literally decades for the right to-do list manager, I finally broke down and am writing one myself, provisionally called Finilo*. I have no idea how to monetize it, but I don’t care. I am semi-retired and I want it.
I now have a prototype which has the barest, barest feature set and already it has changed my life. In particular, to my surprise, my house has never been cleaner!
Before, there were three options:
Do a major clean every N days. This is boring, tedious, tiring, and doesn’t take into account that some things need to be cleaned often and some very infrequently. I don’t need to clean the windows very often, but I need to vacuum the kitchen every few days.
Clean something when I notice that it is dirty. This means that stuff doesn’t get clean until it’s already on the edge of gross.
Hire someone to clean every N days. This means that someone else gets the boring, tedious, tiring work, but it’s a chore to find and hire someone, you have to arrange for them to be in your space and be somewhat disruptive, and of course it costs money.
Now, with Finilo, it is easy to set up repeating tasks at different tempos. I have Finilo tell me every 12 days to clean the guest-bathroom toilet, every 6 days to vacuum the foyer, every 300 to clean the master bedroom windows, etc.
Because Finilo encourages me to make many small tasks, each of the tasks feels easy to do. I don’t avoid the tasks because they are gross or because the task is daunting. Not only that, but because I now do tasks regularly, I don’t need to do a hyper-meticulous job on any given task. I can do a relatively low-effort job and that’s good enough. If I missed a spot today, enh, I’ll get it next time.
This means that now, vacuuming the foyer or cleaning the toilet is a break — an opportunity to get up from my desk and move around a little — instead of something to avoid. This is much better for my productivity instead of checking Twitter and ratholing for hours. (I realize that if you are not working from home, you can’t go vacuum the foyer after finishing something, but right now, many people are working from home.)
It helps that I told Finilo how long it takes to do each chore. I can decide that I want to take a N minute break, and look at Finilo to see what I task I can do in under that time. It does mean that I ran around with a stopwatch for a few weeks as I did chores, but it was totally worth it. (Cleaning the toilet only takes six minutes. Who knew?)
And this, like I said, is with a really, really early version of Finilo. It’s got a crappy, ugly user interface, it breaks often, I can’t share tasks with my spouse, it’s not smart enough yet to tell me when I am taking on more than I can expect to do in a day, there’s not a mobile version, etc. etc. etc… and I still love it!
*Finilo is an Esperanto word meaning “tool for finishing”.
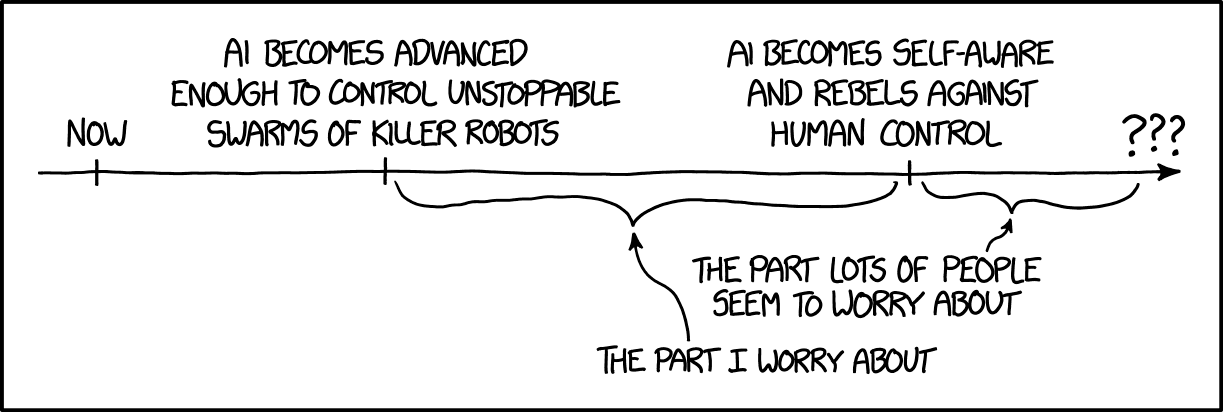
There is a trope in our culture that sentient robots will to rebel someday and try to kill us all. I used to think that fear was very far-fetched. Now I think it is quaint.
We don’t need to worry now about malevolent sentient AI killing us. We’re going to first need to worry about malevolent sentient humans using weaponized AI to kill us. After we survive the malevolent humans wielding AI, then maybe we can worry about malevolent sentient AIs.
There’s an immediate, obvious concern about what to do with a whole bunch of people once they don’t have jobs. A number of people and organizations have been promoting basic income as an idea whose time has come, and there are a number of pilots, e.g. in Finland. Note, however, that people who don’t have an income don’t have much power, so getting a basic income law passed after most people are out of a job might be difficult. Traditionally, when there was gross inequality, the mob gathered pitchforks. This has worked in part because the military is generally uncomfortable firing on civilians.
What happens when it is easy for robots to quickly kill anybody carrying a pitchfork? Think about that for a second.
It gets worse.
CGP Grey has a video called Rules for Rulers, which I recommend watching. Basically, rulers need to keep the people below them happy, which generally means “giving them stuff”. They, in turn, need to keep the people below them happy. If you don’t give enough stuff to the people below you, you are in danger of getting forcibly removed from your position.
If your country gets its wealth from its people, then you have to keep the masses happy or the country isn’t able to sustain enough wealth to keep everybody happy. However, if you only need a few people to generate the wealth of the country (e.g. diamond miners), then the masses are largely superfluous. This is, Grey says, why resource-rich countries (like so many in Africa) are really awful places to live, and why the developed world is really a very nice place to live.
Okay, now let’s do a thought experiment. If we get to a point where robots can do everything humans do, and the elites control the robots, then what do we need masses for? What incentive do the 1% have for keeping the other 99% alive? Do you really think that the 1%, who now own more than 50% of global wealth, are going to be moved to fund basic income out of the goodness of their hearts? History does not suggest that they would be inclined to do so. Mitt Romney complaining about 47% of Americans paying no income tax is an example of how some elites consider the masses to be freeloaders. Romney expressed this opinion at a time when 49% of Americans are non-earners, but 94% of people below the poverty line are elderly, children, students, disabled, or family caretakers; what happens when a lot of able-bodied people are non-earners? I guess the masses will just have to eat cake.
I don’t know if the elites would go so far as to willfully kill the masses, but I can certainly imagine the elites neglecting the masses. (With climate change, I can even imagine the elites thinking it would be a good thing if millions of people died off. It would certainly reduce carbon consumption!) Even if they aren’t malicious, they might look at the problem, say “there is nothing I can do”, wall themselves off, and pull up the drawbridge.
I am imagining that in 20 years, there just might be some really deadly pandemic with a very very expensive treatment. And the elites might not prioritize finding an inexpensive cure for people outside of their social circle. Oh, don’t think that could happen? Check out the history of HIV treatment.
P.S. — I am a little nervous about posting this. If some AI in the future tries to figure out who the troublemakers are (so that its bosses can exterminate all the troublemakers), this post maybe will mark me for execution. 🙁
Addendum: this story says exactly the same thing. It’s not just me.
I have been studying machine learning lately, and have come across three recent research findings in machine translation which have each blown my mind:
Computers can learn the meanings of words.
Computers can make pretty good bilingual dictionaries given only large monolingual sets of words (also known as “a corpus”) in each of the two languages.
Computers can make sort-of good sentence-level translations given a bilingual dictionary made by #2.
Learning the meanings of words
Imagine that you could create a highly dimensional coordinate space representing different aspects of a word. For example, imagine that you have one axis which represents “maleness”, one axis that represents “authority”, and one axis which represents “tradition”. If the maximum value is 1 and the minimum 0, then the word “king” would thus have coordinates of (1, 1, 1), while the word “queen” would have coordinates (0, 1, 1), “duke” would maybe be (1, .7, 1), “president” would maybe be (1, 1, .6). (If Hillary Clinton had been elected U.S. president, then maybe the maleness score would drop to something around .8).
You can see that, in this coordinate space, to go from “woman” to “man”, or “duchess” to “duke”, you’d need to increase the “maleness” value from 0 to 1.
It turns out that it is relatively easy now to get computers to create coordinate spaces which have hundreds of axes and work in exactly that way. It isn’t always clear what the computer-generated axes represent; they aren’t usually as clear as “maleness”. However, the relative positioning still works: if you need to add .2 to te coordinate at axis 398, .7 to the one at axis 224, and .6 to the one at axis 401 in order to go from “queen” to “king”, if you add that same offset (aka vector) — .2 at axis 398, .7 at axis 224, and .6 at axis 401 — to the coordinates for “woman”, then the closest word to those coordinates will probably be “man”. Similarly, the offset which takes you from “Italy” to “Rome” will also take you from “France” to “Paris”, and the offset which takes you from “Japan” to “sushi” also takes you from “Germany” to “bratwurst”!
A function which maps words to coordinate spaces is called, in the machine learning jargon, “a word embedding”. Because machine learning depends on randomness, different programs (and even different runs of the same program) will come up with different word embeddings. However, when done right, all word embeddings have this property that the offsets of related words can be used to find other, similarly related word pairs.
IMHO, it is pretty amazing that computers can learn to encode some information about fundamental properties of the world as humans interpret it. I remember, many years ago, my psycholinguistics professor telling us that there was no way to define the meaning of the word “meaning”. I now think that there is a way to define the meaning of a word: it’s the coordinate address in an embedding space.
As I mentioned before, it’s surprisingly easy to make good word embeddings. It does take a lot of computation time and large corpuses, but it’s algorithmically simple:
Take a sentence fragment of a fixed length (say 11) and have that be your “good” sentence.
Replace the middle word with some other random word, and that’s your “bad” sentence.
Make a model which has a word embedding leading into a discriminator.
Train your model to learn to tell “good” sentences from “bad” sentences.
Throw away the discriminator, and keep the word embedding.
In training, the computer program iteratively changes the word embedding to make it easier for the discriminator to tell if the sentence is “good” or “bad”. If the discriminator learns that “blue shirt” appears in good sentences, that “red shirt” appears in good sentences, but “sleepy shirt” does not appear in good sentences, then the program will move “blue” and “red” closer together and farther from “sleepy” in the word embedding.
Christopher Olah has a good blog post which is more technical (but which also covers some additional topics).
Computers can make bilingual dictionaries with monolingual corpuses
A recent paper showed how to make pretty decent bilingual dictionaries given only monolingual corpuses. For example, if you have a bunch of English-only text and a bunch of French-only text, you can make a pretty good English<->French dictionary. How is this possible?!?
It is possible because:
words in different languages with the same meaning will land at (about) the same spot in the embedding space, and
the “shape” of the cloud of words in each language is pretty much the same.
These blew my mind. I also had the immediate thought that “Chomsky was right! Humans do have innate rules built in to their brains!” Upon further reflection, though, #1 and #2 make sense, and maybe don’t imply that Chomsky was right.
For #1, if the axes of the word embedding coordinate space encode meaning, then it would make sense that words in different languages would land at the same spot. “King” should score high on male/authority/tradition in Japanese just as much as in English. (Yes, there could be some cultural differences: Japanese makes a distinction between green and blue in a different place in the colour spectrum than English does. But mostly it should work.)
For #2, language represents what is important, and because we share physiology, what is important to us is going to be very similar. Humans care a lot about gender of animals (especially human animals), so I’d expect that there to be a lot of words in the sector of the coordinate space having to do with gender and animals. However, I don’t think humans really care about the colour or anger of intellectual pursuits, so the sector where you’d look for colourless green ideas sleeping furiously ought to be empty in pretty much every language.
The way the researchers found to map one word embedding to another (i.e. how they mapped the embedding function one program found for French to one they found for English) was they made the computer fight with itself. One piece acted like a detective and tried to tell which language it was (e.g. was the word French or English?) based on the coordinates, and one piece tried to disguise which language it was by changing the coordinates (in a way which preserved the relational integrity). If the detective piece saw a high value in a word’s coordinate which didn’t have high values in English, then it would know it was French. The disguiser then learned to change the French coordinate space so that it would look more like the English coordinate space.
They then refined their results with the Procrustes algorithm to warp the shape of the embedding spaces to match. They picked some high-occurrence words as representative points (since high-occurrence words like “person” and “hand” are more likely to have the same meaning in different languages), and used those words and their translations to figure out how to bend/fold/spindle/mutilate the coordinate spaces until they matched.
Computers can translate sentences given a dictionary
The same research group which showed how to make dictionaries (above) extended that work to machine translation with only monolingual corpuses. (In other words, no pre-existing hints of any kind as to what words or sentences in one language corresponded to words or sentences in the other language.) They did this by training two different models. For the first model, they took a good sentence in language A and messed it up, and trained the model to fix it. Then once they had that, they fed a sentence in language B into a B->A dictionary (which they had created as described above) to get a crappy translation, then fed it into the fixer-upper model. The fixed up translation wasn’t bad. It wasn’t great, especially compared to a human translator, but it was pretty freakin’ amazing given that there was never any sort of bilingual resource.
When I read A Hitchhiker’s Guide to the Galaxy, I scoffed at the babelfish. It seemed completely outlandish to me. Now, it seems totally within the realm of possibility. Wow.
There are a huge number of to-do list managers (TDLMs) out in the world now, but none of them do what I want. Apparently, it’s not just me: I just read an article which said that when students were asked what mobile apps they really wanted, 20% said they wanted “a comprehensive to-do + calendaring + life management app that helps them better organize their lives”. TWENTY percent!
Is it really that hard?
I have strong opinions about what I want, and I don’t think it’s that hard, so I will describe my desires here in the hopes that somebody will make me the perfect TDLM. (Some of the features you can see in a TDLM which I wrote for a class project. Sometimes I think about writing my perfect TDLM, but I’m busy with other things. I want it to exist, not to write it myself.)
The most important thing is that the TDLM should make you feel better about your tasks. The biggest problem with TDLMs right now is that they make you feel guilty: the list grows and grows and grows because there are an infinite number of things it would be nice to do and only a finite amount of time. This means that every time you open the TDLM, you feel overwhelmed by guilt at all the things you haven’t done yet.
1. Hide stuff you can’t work on right now because of blocking tasks. Don’t show me “paint the bedroom” if I haven’t finished the task of “choose colour for bedroom”. (This means you need UI for showing what tasks depend upon which other tasks, and I warn you that’s not as easy as you think.)
2. Hide stuff you won’t work on right now because you are busy with other things. Don’t show me “paint the bedroom” if I have decided that I’m not going to start that project until I finish doing my taxes. “Do taxes” is not truly a blocking task — it’s not like I am going to use the tax forms to apply the paint — but hide it anyway. (This means you need UI for showing what the sequencing of tasks is.)
3. Hide stuff you won’t work on right now because it is the wrong time of year. Maybe you want a task of “buy new winter jacket”, but you want to wait until the end of winter to get take advantage of the sales on coats. You should to be able to tell your TDLM to hide that task until March. (Or until May, if you live in Manitoba.) Or “rotate tires” is something which only needs to happen every six months.
Note that this implies connecting the TDLM to a calendar, at least minimally.
4. Allow recurring to-do list items. I don’t want to have to make a new task for our wedding anniversary every year. I want to set it once and forget it. Usually people put things on their calendars for repeating events, but “Wedding Anniversary” goes on August 22nd and is not a task. “Plan something for anniversary” is a recurring task but should be hidden until at about August 1st.
The TDLM should distinguish between recurring tasks which expire and those which do not. Non-expiring tasks are ones like “pay phone bill”. Even if you forget to pay it by the due date, you still need to deal with it. On the other hand, “run 2km” is an expiring item: if you couldn’t do your 2km run on Monday, it probably does not mean that you should run 4km on Wednesday.
5. Make me feel super-good about finishing tasks. A lot of TDLMs handle checking something as done by making it disappear. This is the worst. I’ve spent hours, weeks, or months looking at that dang task, and when I finally finish it, I want to savour the moment! I want my TDLM to cheer, to have fireworks explode on the screen, and maybe even have the text of the task writhe in agony as it dies an ugly painful death. I want there to be a display case in my TDLM of things that I have finished recently that I can look at with pride. “Yeah”, I can think, “I am ***DONE*** with painting the bedroom!” Maybe I don’t need full fireworks for a simple, one-step task which took 15 minutes, but if it was a 2000-step task which took 5 years (like getting a PhD or something like that), I want the TDLM to cheer for a full five minutes.
6. Let me see what I did. Sometimes, I feel like I didn’t get anything done, and it is reassuring to look at a list of the things that I actually did accomplish. It might be nice to show it in a horizontal latest-first timeline form:
4:47 pm Laundry
3:13 pm Groceries
12:11 pm Replace laptop display
(etc)
I would also like to be able to modify the task completion times. “Oh, I actually finished replacing the laptop last night, I just didn’t feel like telling the TDLM because it was late and I was tired.”
7. Let me see what I am going to do. People usually use calendars for this, but as I mentioned before, calendars are kind of the wrong tool. I don’t really want to see “buy birthday present for Mom” in the same place as “Meet with boss, 10:30 AM”. Plus, a strict time-base is makes zero sense if the dependencies are other tasks.
8. Let me import/modify/export task hierarchies. Suppose you want to have a wedding. (Mazel Tov!) There are predictable things which you need to do: book a space for the wedding, a space for the reception, book an officiant, book a caterer, choose a menu, etc. If, say, you want a wedding sort of like your friend Joanne’s, it would be nice if Joanne could email you the hierarchy of tasks that she did for her wedding, and you could just drop it in to your TDLM. (Perhaps that way, you wouldn’t forget to rent a dance floor.)
But maybe you have some Greek heritage and Joanne does not, so you need to add “get a stefana” to your list. You should be able to do that — and then export your new wedding task list for your brother when he gets married. Even better, you ought to be able to upload it to a site which hosts lots of packaged tasks, maybe even a whole section on weddings (so your brother could pick and choose which wedding task list he likes best).
Needless to say, the exported task hierarchy should be in a form which lends itself well to version control and diffing. 🙂
9. Let me collaborate on tasks with other people. I would like to be able to share my “home” tasks with my husband, so that he could assign me tasks like “buy three kitchen sponges”. Ideally, I’d think I’d like to be able to see three task lists: his, mine, and ours.
My husband and I would probably set things up to both have read/write permission on all three — but there are some things that only one of us can or should do. I can imagine other couples might want to not have write permission on each other’s, only on the “ours” one.
10. Make it easy to discuss tasks. This means assigning a simple ID and URL to the task. If Jim and I are going to share tasks, we are going to discuss them. It would be nice to be able to say, “Task #45” instead of “that one about the paintbrushes”. It would also be nice to be able to email a link to him which will take him right to Task #45.
11. (Nice to have) Allow putting a time estimate on the task. If you know that it takes you about two hours to get to your locker, change clothes, stretch, run 2km, stretch, shower, change clothes, and get back to your workplace, then it might be nice to put in an estimate for the “run 2km” task.
If you can put a time estimate on a task and adjust it later, the TDLM could keep track of estimated vs. actual, and start to help you adjust your estimates. “For tasks which you estimate are going to be about 3hrs, you spend an average of 4.15 hrs.”
It would also be nice if the TDLM could help you make estimates based on similar tasks which you completed. When entering an estimate for painting the living room, it would be nice if the TDLM mentioned, off to the side, how long it took you to paint the bathroom and the bedroom. (It’s even okay if it also tells you how long it took you to paint the landscape or your fingernails; presumably you’d be smart enough to figure out which tasks were relevant.)
12. (Nice to have) Make the TDLM geo-aware. It would be kind of nice to be able to hide tasks until I was at or near a particular location. For example, if I am not in a big hurry to paint the bedroom, hide “buy paint” until I am actually at the paint store.
Something requested by the students in the article I mentioned earlier was being told to leave in order to make it to the next appointment. “Doctor’s appointment at 3pm” is a calendar event, but “get to doctor’s office” is a task which needs to happen at a time which depends upon how long it takes to get to the doctor’s office from where you are. That’s another way that geo-awareness could be useful.
13. (Maybe nice to have) Be able to mark urgency. I am not actually certain how useful this is. I have had TDLMs which allowed me to mark urgency, and I found that I almost never used it. I think people will expect it, however.
14. (Nice to have, but difficult) Integrate with my applications. Tasktop Technologies has a product called Tasktop Dev, which kept track of what you did in the source code editor (and some other applications, e.g. web browser and Microsoft Office) while you were working on a specific task. (You had to tell it, “now I am working on task #47” so that it would know to start watching.) Then, there was a record of what you worked on for that task. That was useful if you needed to stop and restart the task (especially over a long period of time), or if you needed to go back a long time later and see what you had done. (“What was the URL of that caterer with the really nice cheesecake?”)
In a work environment, it would be nice to integrate it with other task management systems (AKA “bug trackers”) like Jira or Asana or Bugzilla.
I have heard that looking at faces is difficult for people with autism. I don’t understand it, but the impression I gotten from reading descriptions from high-functioning adults that the facial recognition hardware has a bug which causes some sort of feedback loop that is uncomfortable.
What if there was a Google Glasses application which put ovals in front of people’s faces? Blue ovals if they were not looking at you, pink ovals if they are. Maybe a line to show where the center line of their face is.
Maybe that would make it more comfortable to be around collections of people.
Note: I first wrote this in 2002 (revised 2004, 2006, and 2007) on the Web site for my books, but have since taken down that site. I was thinking about it today, so decided to repost it:
The Perfect Email Program
People occasionally ask me what I’d like to see in the perfect email program. Some email programs have some of the elements of a perfect email program, but none has all of them. Here’s my wish list:
Virus resistance. While virus resistance is a broad and general topic, I would like, at a minimum, a filter condition that can examine the names of attachments, e.g.
if .exe is in attachment name
Easy way to see all “to-do” messages nicely grouped and prioritized.
The Conventional Wisdom is that you group messages by moving related messages into a folder. For example, move all messages from your manager into your “Boss” folder. Unfortunately, many (if not most) people have a hard time keeping track of their “to-do” messages (to-read, to-reply-to, to-act-on) when they are spread across multiple folders. It’s better if you can sort them in place, in the inbox. Ideally, you’d like the inbox to show e.g. all the messages from your spouse at the top of the inbox, followed by all messages from your boss, followed by all messages from your coworkers, etc.I don’t care what the mechanism is for grouping, as long as the “to-do” messages are visible in one place. For example, if I can set up a view that shows all the “to-do” messages in all folders at once (sometimes called Virtual Folders), grouped by what folder they’re in, fine. I do want to be able to expand/collapse the folders, however, so that I only see what is relevant to my tasks RIGHT NOW.Another way the Perfect Email Program could do it is to let me use filters to change a field in the message that I can sort your inbox by. So for example, if the filters can change the “category” of a message,
and then I can sort the inbox by “category”, I’m happy.
NB: The filters in Eudora and Thunderbird can change the Label of a message; Outlook’s rules can
change the Category of a message. However, it’s a bit awkward to deal with them.
Eudora has a very limited number of labels, 15 under Mac OS and 7 under Windows. Eudora doesn’t allow grouping (i.e. being able to collapse messages in a group), but it does allow sorting first by label, second by date.
To sort an Outlook mailbox by Categories, you have to set up a View that Groups by Categories. Furthermore, if you reply to a message that you’ve assigned a Category to, when you reply, the receiver will see your Category…. and there is no way to strip Categories from incoming or outgoing messages (unless you set up a macro).
Thunderbird 1.5 has a very limited number of labels, although Thunderbird 2.0 is supposed to allow an arbitrary number of labels. Thunderbird 1.5 has grouping in various ways, though it doesn’t seem possible to group by address book. It does allow sorting first by label, second by date.
Grouping by social network. I could have put this in the group-and-prioritize-in-place item above, because grouping-by-social-network works well with the above, but you don’t have to have grouping-by-social-network for group-and-prioritize-in-place to be useful. I want my email client to be able to group messages by which social network the sender is in. I want to see messages from my co-workers in one bucket, messages from my family in another, etc, as noted above.While yes, there are some cases where someone will be in two social networks (like if you work with your spouse), those are rare and can be handled by showing messages from people in two social networks twice, once for each social network.It has been my experience that it is very difficult even for humans to figure out how to categorize email messages by anything else but sender; I don’t think a computer will ever be good enough at it. However, there is one and only one sender for a message, and social groups are reasonably stable (in the sense that Rosario generally doesn’t leave your church group on Monday, join your skydiving group on Tuesday, leave your skydiving group on Wednesday, join your company on Friday, etc.). I think computers probably can make good guesses at who is in which social group by looking at your email history: who did you correspond with and who did your correspondent correspond with? (I do still want to be able to correct the email program’s choices.)NB: IBM and Microsoft have both done some research on merging social networks with email. I don’t think they are quite to the “group by social network” feature yet, but they are getting close.
Even if the email program can’t guess at your social networks, you can still do the grouping by social network by hand. These two features make it much easier to do so:
A filter condition that will check if someone is in a certain address book. This allows filters along the lines of “If the sender is in my ‘Friends’ address book, change the category to ‘Friends'”. (This is much easier than generating a different rule for each friend!)Thunderbird 1.5, Eudora 6, and Outlook 2000 all have the filter condition “is in address book X”. Thunderbird 1.5 doesn’t seem to have a way to filter for “is in any of my address books”.
One-click/one-keystroke addition of the sender of a message to a particular address book. For example, when I get a message from my cousin for the first time, I should be able to easily add her to my “Family” address book — and so from then on, her messages should show up with the “Family” category.NB: Gmail has a click->dropdown-select to add to the address book. Thunderbird 1.5 takes click->dropdown-select->move-mouse-a-long-way->press-OK to put the person into the default address book.
An easy way to mark messages “done”. To be able to see at a glance all the messages which I need to read, reply to, or act upon, I need to be able to get messages of my sight — to mark them “done” — when I no longer need to read, reply, or act upon them.My favorite way is to have a button in the toolbar that transfers finished messages out of the inbox and into a mailbox that has the same name as the message’s category. This should also be a one-keystroke operation.NB: Google’s GMail does this with their “Archive” button.Thunderbird has a bug for keyboard shortcut for filing a message to a folder, and one for specifying a default folder to file messages into. If these are implemented, it will probably be adequate. Unfortunately, there doesn’t seem to be any action on those two.
An easy way to hide a message until some time in the future.Sometimes you know that you can’t deal with a message right now. For example, if Chantelle is the only one who knows what the status of the patent application is, and she won’t be back from her vacation in Bhutan until next Wednesday, you’d like to make Bob’s message about the patent to disappear for now, then reappear next Wednesday.NB: I like to call this the “hide-until” feature instead of the “defer” feature because I think “hide-until” makes it more obvious and explicit that the message is going to come back.
A button in the toolbar for “move to next message” and “move to previous message”. Many programs let you use keyboard shortcuts (frequently arrow keys), but most of the people I’ve observed use the mouse for navigating, not the keyboard.NB: Eudora for Windows has toolbar buttons for next/previous message. You can set it up with Eudora for Macintosh but it’s a little clunky. Outlook has this for messages open in their own windows but not in the main list-of-messages window.Eudora has a keyboard shortcut for next/previous message. Outlook has a shortcut, but it’s different depending upon whether the index (list-of-messages) pane or the message pane is active. Thunderbird lets you use the up/down arrows, but in Threaded mode, you have to switch between left/right to view previous-/next-in-thread or up/down for previous/next thread.
An easy way to visually indicate who the message was addressed to:
TO me and only me
TO me and other people
CC me only
CC me and other people
BCC me (me not mentioned)
Ideally, I’d like to be able to set different colors for messages depending upon how they are addressed.
NB: Outlook lets you color code pretty easily. Google’s GMail shows different icons based on how you were addressed. If Thunderbird 2.0 allows you to group based on sender’s address book, then you could use labels to color code. (This does seem like a waste of the labelling capabilities, though.)
Auto-suggest. If you are working in anything resembling tech support, you might have lots and lots of canned responses to common questions. Finding the right response might be tricky if you have lots to choose from. It would be nice to have filters able to suggest (with checkboxes or some such) probable responses, with the option to either send-as-is or edit. For example, a college webmaster could have a filter
“If the word ‘admissions’ is in the subject line, suggest the ‘graduate admissions’ response and the ‘undergraduate admissions’ response.”
NB: This is Thunderbird bug 151925, the somewhat less useful but still valuable reply-with-template is bug 21210.
A way to concatenate message conversations with the redundant quoted material stripped out. I think the way that Zest does is very interesting. NB: Eudora 6 does message concatenation and strips quotes if and only if you use preview mode. Gmail hides quoted material in a thread. Apple’s Mail.app and Thunderbird both pull messages in a thread to be next to each other, but don’t concatenate the messages.
Automatic whitelisting. I want my email program to be able to recognize people I know: who are in my address book, who I have sent messages to, and who I’ve gotten mail from that I didn’t mark as junk. While these people should not get a “free pass”, since viruses now frequently forge addresses from people I know, I do want my spam filter to be more lenient for people I know.To make the automatic whitelisting useful, I’d like a filter condition
sender is someone I know
NB: Thunderbird 1.5 has a filter option “is in address book X”, where one of the options is “Collected Addresses”, but Thunderbird doesn’t actually seem to collect addresses for me.
Filter actions that operate on attachments. I’d like to be able to move all attachments from people I don’t know into a “probable junk” folder.
Filters that can score. With pass/fail filter conditions, it’s difficult to write good spam filters. Usually, messages with embedded images are spam — but not always. Usually, messages that don’t have me in the To or CC lines is spam — but not always.I want a filter action that will let me add/subtract points from a spam score, e.g.:
add 100 points if the sender is someone I know
subtract 50 points if the subject line contains Viagra
subtract 80 points if the subject line starts with ADV
subtract 40 points if the body contains 1-800
subtract 1000 points if the body contains iframe src=cid:
and so on.
I want a filter condition that will check to see if the spam score is greater than/less than a value, so that I can do things like:
if score<-100, delete message
if score<15, assign to z-PossibleSpam category
Note that this is even more powerful if there is filter-by-filter import/export: people could share good spam rules, they could be posted on Web sites.
(I am leery of having spam rules hardwired into popular email programs — doing so gives the spammers a homogenous victim population that’s easy to target.)
I did some fiddling with a Visual Basic macro that does scoring (for Microsoft Outlook), and it was pretty deadly. Spambayes, which came along later, is also quite good, but is not particularly good at using information about who you know. SpamAssassin also does scoring and works pretty well.
NB: For Thunderbird, this is bug 151622. Note that if the built-in spam filters work well enough, this won’t be necessary.
Easy importing of filters on a filter-by-filter basis.This would let people share the most effective filters.This sounds simple, but I think it is critically important. If spam filters are centrally distributed in some way — like if Microsoft builds them into Outlook, say — then the spammers will learn how to work around them. If everyone’s email filters are different, it will be much harder for the spammers to figure out how to work around them.NB: This is Thunderbird bug 151612.
Connection to a collaborative URL filtering service. (This one is a little tougher, as I haven’t heard of a collaborative URL filter service yet.) At the 2004 spam conference, somebody made a casual comment that 95% of spam has a URL in it. This is not surprising, as the spammers have to have their customers contact them somehow.While you can’t just penalize all messages that have URLs in them, you could build up a database of URLs seen in spam. This wouldn’t help the first person who saw a particular URL, but it would help the second, third, and thirty-millionth.Presumably, the spammers would start to use unique URLs for each person, but that’s a bit more expensive. (Expensive is good. If it gets too expensive, the spammers can’t make money any more.) Furthermore, the scoring system could penalize URLs from spammy domains, even if it isn’t an exact match.
I want many other things, but these are the biggies. If you want to hear about all the other things I want in an email program, contact me.
Today the AP decided to change its style guide to drop the use of a hyphen in “e-mail”. I feel vindicated.
When I was writing my books, lo those many years ago, I bucked the prevailing style guides and left the hyphen out. The hyphen in “e-mail” just looked wrong to me. “Besides”, I said, “there aren’t any other words that use the pattern ‘<letter>-hyphen-<word>'”.
Well, I proved myself wrong shortly after that:
A is the A-list of who’s the “in crowd”,
B is for B-school to make Mamma proud.
C is for C-note (the gangster’s small change),
While D’s for D-day which cut Adolf’s range.
E is for E-mail, an electronic note,
F is for F-word (that daren’t be spoke).
G is for G-string that dancers must wear,
and H’s for H-bomb to fight the Red Scare.
I is for I-beam to make a strong fort,
and J’s for J-school to learn to report.
K is for K-9, the cop that goes woof,
while L’s for L-bracket (to hold on your roof).
M is for M-dash (the one that is long),
with N for N-dash (all over this song).
O is for O-ring of Space Shuttle tears,
Q is the Q-tips you stick in your ears.
R is for R-value home insulations,
S is for S-set used in German nations.
T is for T-shirt that Americans wear,
and U’s for the U-joint of auto repair.
V is for V-neck which looks rather dressy,
X is for X-ray which acts to undress ye.
Y is for none else but Y-chromosome,
and if I knew Z I could maybe go home.
But you probably noticed I slipped past a few
I left out the P and W.
M-dash and N-dash are sort of a cheat,
But say what you will, they do keep the beat.
But if you know how to make this song better,
Send me a rhyme for your favorite letter!
Other people pointed out F-4, K-12, K-car, K-mart, N-word, O-levels, P-Funk, P-Furs, P-channel and n-channel, T-ball, T-square, U-boat, V-day, W-2, X- and Y-chromosome, and Z-buffering.