My beloved and I, at my instigation, took a little vacation on Friday. I wanted to celebrate finishing our taxes, the weather had been beautiful and sunny (although still slightly cool, c’mon, it’s British Columbia in March), and we hadn’t been out at all together in a very long time.
So we rented a carshare, ostensibly to cruise around and look at cherry blossoms.
But of course there was scope creep. Oh hey, if we look at cherry blossoms out at UBC, then we should get takeout from my fave campus restaurant and eat at the little park next door. And of course get ice cream from my fave ice cream shop. Oh, and if we have a car, we should go visit J&A (distanced, in their back yard), who my beloved hasn’t seen in person for a year. And because they can’t invite us in, let’s get takeout on our way home! Oh, except beloved as a doctor’s appointment at 3pm, so we’ll need to add that in. Oh, and as long as we have a car, we should pick up bulk kidney beans and yellow raisins at the Punjab Food Centre.
We are still in a pandemic, so there were a few things that we knew would be different, even in the planning stage. In Before Times, maybe we would have stayed at J&A’s for dinner. In Before Times, we would have eaten at the restaurant. I also carefully checked fave restaurant’s web site to make sure they were still open.
I gave a passing thought to toilets. We should probably pee at fave restaurant at lunch. I considered whether that was safe, and decided it was. Their washroom was relatively large and lightly used even when in Before Times.
Well. When we got to fave restaurant, there was a sign which said that it had closed on 7 Dec. Grrrr, thanks for keeping your website updated, not.
And I needed to pee!
The UBC hospital is very close, so we headed over there. I felt a little bad about sneaking in, but I had been a patient there before, and I really did need to go. But a sign which said, “NON-ESSENTIAL VISITS PROHIBITED.” While finding a toilet was essential for me right then, I was pretty sure they wouldn’t find it essential. I could not enter in good conscience, even though I was wearing a good mask.
So instead, we went to the UBC Health Clinic, where we are both current patients. They have big washrooms with low usage, so I felt pretty sure it was safe. Success!
That gave us enough breathing room to find a fast food joint near the ice cream shop. We ate a leisurely lunch outside, had ice cream outside, and then… I needed to pee again. After a little bit of discussion, we decided to swing past home and pee there. (It also let my beloved pick up his wallet, which he had forgotten at home because he doesn’t go out that much because pandemic.)
I thought about staying home and having him swing around afterwards and pick me up, but then decided that if I went with him and waited in the car (because pandemic), then we could head straight over to J&A’s.
Did I mention that my beloved got the food at the restaurant? And so when I asked for a cola, dutifully got me a cola? Which came in a 591ml bottle instead of the 222ml mini-cans which I usually drink?
Yep, after Jim got done with his doctor’s appointment, I had to pee again. And since J&A couldn’t let us in their house…. yep, we swung past home again.
After we left J&A, I was able to hold it until we got home, but I was definitely paying attention to my bladder.
“You have to plan potty breaks really carefully” is not the pandemic advice I ever expected during Before Times.
I know we are having a pandemic, but I am getting tired of masking. I will take it out on you, Dear Reader, because, well, I can.
A few years ago, when there were really bad wildfires, my spouse and I bought eight N95 masks for particulates (i.e. with vents in them).
When the pandemic hit, I taped up the vents and used them in particularly scary situations (like when I went to the doctor for something).
Even reusing the N95s for a while, we used up most of our stock of N95s. I didn’t want to use them all up, so I researched alternatives, and found that a simple cheap surgical mask was allegedly as good as an N95 if you wore a mask brace over it. Awesome.
I bought a mask brace, put it over a surgical mask, and went for a long walk to test it. The brace did a great job of eliminating gaps, and it made my glasses fog less, but the brace also held the mask so close to my mouth that I couldn’t avoid getting my lips on it. At the end of a 90-min walk, it was wet. I hear that they are less effective after you get them wet.
I still had one of my old N95s, so I pulled the tape off and now wear it under my surgical mask under the brace, purely for structural reasons, to keep the surgical mask away from my mouth. Great!
Well, except that if it’s raining, as it does frequently in the Pacific Northwest in the winter (aka “always”), the N95 keeps the mask far enough from my mouth that it sticks out farther than my hat can shield it, and the rain gets on it. So if it starts to rain, I need to take the mask off.
(I am not too worried about being outdoors in the rain without a mask. First, the outdoors is very well-ventilated. Second, when it’s raining, there are fewer people out and about. Third, I figure that the rain will hit some of the virus particles and knock them down.)
So anyway, that’s the context.
Here’s what I did today.
Got ready to leave the apartment and get into a small, poorly-ventilated enclosed space (the elevator). Took off glasses, put on N95/mask/brace/glasses/hat.
Got outside the apartment building. It was raining. Took off hat/glasses/brace/mask/N95, replaces glasses and hat.
Walked to hospital, prepared to enter hospital. Took off glasses/hat, put on N95/mask/brace/glasses/hat.
Sinus doctor wanted to stick things in my nose. Took off hat/glasses/brace/mask/N95, replaced glasses.
Sinus doctor removed nasal truffles (but that’s a whole different story). Doc said that he didn’t think he got them all but he thought that to get the rest he’d have to anesthetize me. Took off glasses, put on N95/mask/brace/glasses/hat.
Went outside. No longer raining. Stifled a massive sneeze, and somehow a nasal truffle ended up in my mouth. Took off glasses/hat/N95/mask/brace. Replaced glasses.
Spat out the nasal truffle, examined it, took photo. Took off glasses, put onN95/mask/brace/glasses/hat.
Walked over to cell phone store to get my cracked phone screen replaced. They told me to wait an hour. Went outside and wandered around for a little bit before deciding to grab some lunch. It started raining again. Took off hat/glasses/brace/mask/N95, replaced glasses/hat.
Decided on pizza. Under the pizzeria’s awning, took off glasses/hat, put on N95/mask/brace/glasses/hat.
Got my slice, went and sat at a table outside under the awning. (Yes, it is cold but I’ve got good gear on.) Took off hat/glasses/brace/mask/N95, replaced glasses/hat.
Finished my lunch. Went back to phone store. Took off glasses/hat, put on N95/mask/brace/hat/glasses.
Got my phone, left shop. Still raining. Took off hat/glasses/brace/mask/N95, replaced glasses/hat.
Walked to drug store. Took off glasses/hat, put on N95/mask/brace/hat/glasses.
Left drug store, disappointed that they did not have face shields in stock which would protect the mask from rain. Still raining. Took off hat/glasses/brace/mask/N95, replaced glasses/hat.
Walked to apartment building. Took off glasses/hat, put on N95/mask/brace/hat/glasses.
Entered our apartment. Took off hat/glasses/brace/mask/N95, replaced glasses.
I realize that putting on/taking off masks is a minor inconvenience compared to, say, not breathing, but it’s still annoying. I am ready for the rain to stop.
Why are there so many? Surely, you say, we don’t need so many candidates. Why did so many companies try? Why don’t most of them quit now. Why don’t the losers just manufacture the winners’ vaccines?
There are several reasons why there are so many.
There are nearly 8 billion people out there. That huge market means a huge opportunity to make money, so many people wanted to invest.
There are lots of different market segments out there, and not all vaccines are appropriate for all markets. For example:
Wealthy countries with good infrastructure are able to cope with the refrigeration demands of the mRNA vaccines, while poor countries might not be able to.
Wealthy countries can buy expensive vaccines, while poor countries might not be able to afford it.
Countries have a financial incentive to fund domestic development of vaccines. COVID-19 costs a huge, huge amount in lives, money, and social well-being, for every single day that the pandemic continues. Compared to being in a pandemic longer, a vaccine development program is cheap.
Countries have domestic security reasons to develop their own vaccines:
Countries would rather not have to inject their citizens with liquids coming from their political rivals. For example, Taiwan might not want not trust vaccines from China.
There are (IMHO legitimate) concerns that other countries might slap export controls on vaccines developed in their home countries, insisting that those vaccines go to their own citizens first. Countries have no control over when they can have access to foreign vaccines, but might be able to exert some control over domestic providers’ priority and sequencing choices.
Players — both countries and companies — have an incentive to invest in vaccine technology to ensure long-term competitiveness, especially for mRNA vaccines. The mRNA vaccines are so good that being able to make them domestically is a huge strength, both in terms of being able to make your citizens healthier in the future and in terms of increasing your country’s economic might.
As for the question of why the losers don’t just manufacture the “winners'” vaccines, in addition to #5 above:
The “losers” might not have accepted yet that they have “lost”. Even if the pandemic eases in the developed countries in the next year, there’s still going to be billions of people who still need the vaccine. So even if the “loser” vaccine doesn’t get to market for a year, there’s still a lot of time to make money on the vaccine after that.
The “winners” might not feel comfortable licensing their manufacturing technology to their rivals. Why should Moderna show Providence Therapeutics how to make mRNA vaccines, when Providence might turn into a competitor later on?
It would make more sense for the “winners” to flat-out buy their competitors. The winners presumably are making money right now, so they ought to be able to afford it.
The “winners” are busy right now. They are making (and selling!) vaccines as fast as they can at the moment. Technology transfer deals — or outright purchases — take time and attention, and companies like Moderna probably do not have any attention to spare at the moment. Look for deals in a year or two. (Right now, Pfizer is doing an internal upgrade to its factory to boost production, causing a short-term drop in supply, causing people to totally lose their collective shit enormous consternation among their customers.)
There is a lot of nervousness right now about new strains of the SARS-CoV-2 virus. There is now very good evidence that the B.1.1.7 (“UK”) strain is more transmissible than the original strain (which I will call the “Wuhan” strain because I haven’t seen anyone give it a name). There are also strains out of South Africa and Brazil which have similar mutations and are similarly worrying.
So I have been wondering how fast Moderna and Pfizer/BioNTech could tweak their strains to produce vaccines targeting the UK strain instead of the Wuhan strain. That has not been entirely straightforward to figure out, but I think I have finally pieced it together from reading, mostly from this and this.
The things that need to be done include:
Get the DNA sequence of the new strain’s spike protein. That’s something which comes from outside the company. (Zero additional time.)
Modify the sequence slightly in completely predictable ways: add a start block on, add an end block, convert all the thymine with 1-methyl-3’-pseudouridylyl, translate some bases into equivalent sequences to get a higher proportion of cytosine and guanine, etc. (See Reverse Engineering the source code of the BioNTech/Pfizer SARS-CoV-2 Vaccine for more on these algorithmic modifications.) (Educated guess: probably fifteen minutes of additional time, not even worth counting.)
Modify the sequence slightly to improve manufacturability. This will be a proprietary step that the company will do. Given how small the physical changes are between the Wuhan strain and the UK strain, I suspect that this step will not take long, and possibly could be skipped. (Guess: 0-1 days.)
Convert the text sequence into physical DNA, the “template DNA”. This is a completely straightforward, common process, but I don’t know how long it takes to get the amount of DNA needed. (Guess: 1-4 days)
Verify that you got the right DNA, I assume using a PCR test. (6 hours, 0.25 days)
After this point, all the rest of the production steps are exactly the same as are already being done for the Wuhan strain. If I were Pfizer or Moderna, I would already have done the previous steps for all of the scary variant strains and have a bunch of DNA on ice, ready to ship out if the green light was given. So it might in fact be zero additional days. (2-6 weeks, 6 weeks)
Addendum 2021-03-02: This article says that finish & fill — testing, getting the serum into the bottles, and labelling — take five weeks.
I have not heard of any official floating the idea of modifying the vaccine, probably because it looks like the Wuhan vaccine will be good enough against the UK strain. (Addendum: the B.1.351 is a different matter.) However, if there started to be rumbling about how the vaccine should be changed, if I were Pfizer or Moderna, I would actually go through all the steps to make enough doses of the UK vaccine for testing if need be.
It might be the first time we do it, we’ll check an immunogenicity study. But it’s not going to have to be another 30,000 patient clinical trial. Those immunogenicity studies are usually 400 patients, just to make sure that we have the right check of what’s coming out. And even that may not be necessary after we check at the first one or two times. So I think we’ll have a way of evolving here with these.
If I understand correctly, immunogenicity studies are tests of the blood which check to make sure that the vaccine causes the desired immune response.
This would mean that the the company would vaccinate volunteers — apparently about 400 — give them enough time for their immune system to react
Recruit test participants. Hopefully they would have volunteers ready to go. (Zero additional days.)
Wait for the test participants’ immune systems to react to the vaccines. (14 days.)
At this point, the test participants’ blood could be tested to see if it mounts the desired immune response. One might think they could stop there, but regulatory agencies probably would want to check after the second dose. Moderna ran their first trials with a 21 day delay; Pfizer did a 28 day delay. (7 or 14 more days) Addendum 2021-03-04: These new vaccines are being positioned as boosters, which means there would not be a second dose.
Give all the volunteers their second dose. (1 day)
Wait for the volunteers’ immune systems to react to the vaccines. (14 days.)
Take blood samples from the test participants. (1 day)
Test blood to see if it mounts the desired immune response. (Guess: 2 days)
Write up report. I think this wouldn’t take long because they could copy and paste a lot from the Wuhan vaccine’s report. (Guess: 2-7 days.)
At this point, it would go to the regulatory bodies.
Add that all up, and it comes out to about 7-8 weeks from finishing the vaccine production to the data delivered to regulators, 3-4 weeks if they only require one dose.
The regulators would need to evaluate the data. Different regulators take different lengths of times, but the Pfizer vaccine took about three weeks from the application to approval by the US Food and Drug administration, and about the same amount of time for Health Canada to approve it. A new strain would have far less data to pore through, so I would guess it would be only a week or so. (Guess: 1-3 weeks)Addendum 2021-03-04: I’m now thinking 1 week is probably too optimistic. Say 1-3 weeks.
In summary, my best guess is 4-6 weeks to manufacture the new vaccine, 7-8 weeks to do clinical trials, and 1-3 weeks for approval, or a total of 12-18 weeks.
Addendum 2021-02-06: According to a Washington Post article on 2021-01-25, Moderna has started working on a vaccine for the P.1 variant.
The scientific and pharmaceutical race to keep coronavirus vaccines ahead of new virus variants escalated Monday, even as a highly transmissible variant first detected in people who had recently traveled to Brazil was discovered in Minnesota.
Moderna, the maker of one of the two authorized coronavirus vaccines in the United States, announced it would develop and test a new vaccine tailored to block a similar mutation-riddled virus variant in case an updated shot becomes necessary.
Addendum 2021-02-07: I forgot that the delay between the first and second dose is not 14 days, it’s 21 (for Moderna) and 28 (for Pfizer). I have adjusted accordingly.
A prime inventor of the technology behind mRNA vaccines, Drew Weissman, of the University of Pennsylvania, said he has been told by the leader of BioNTech that it could take as little as six weeks to formulate a new mRNA payload and manufacture it to target a variant. Pfizer chief executive Albert Bourla told investors earlier this month that he anticipates that a variant-specific vaccine could be approved in 100 days, including clinical testing and regulatory reviews.
Addendum 2021-02-25 from an article dated 2021-02-22: the US FDA has released guidelines on what testing vaccines against variant strains will need to do. They need to vaccinate volunteers with the variant vaccine, and look at the blood to see how big of a response to the virus variants the volunteers’ blood makes. If the response is comparable to the one from the Classic vaccines, it’s a go.Addendum 2021-03-04: There’s a consortium of European non-EU countries which says the same basic thing about approving vaccines against new strains.
However, I am proud of the moon landing. Not personally, but as a human. I am incredibly proud that we — collectively, over the centuries — managed to land on another celestial body.
The moon landing is a great example of this. To get to the moon, we had to build upon many technological achievements. We humans invented writing and governments and paper and books and lending libraries and addition and subtraction and exponents and the zero and protractors and slide rules and furnaces and tin snips and fireworks and rockets and tubes and space suits and we did it! Us humans!
I am also proud, as a human being, of mRNA vaccines.
Not at first — I was a little nervous about the mRNA vaccines when they first got approved for use against COVID-19. The mRNA vaccine was a very new technology, and there was a huge amount of pressure. Did corners get cut, sacrificing safety for speed?
But after reading a bit about it (especially this explanation), I was in absolute awe. The mRNA vaccines are sort of like “pre-vaccines”, which convince our own bodies to make the things we want our bodies to recognize and destroy. Instead of injecting us with millions of SARS-CoV-2 spike proteins, we get injected with instructions for our cells to make bazillions of spike proteins. This makes the mRNA vaccines 95% effective against the SARS-CoV-2 virus.
The mRNA vaccines are so beautiful (and effective) that they make all other vaccines now look primitive to me, like clumsy bumblings of extremely lucky ignoramuses. (“How did they ever work???”, I marvel.)
We humans — collectively, over the centuries — managed to figure out chemistry and anatomy and microscopes and cells and X-Rays and DNA and stop codons and antibodies and sequencing and ribosomes and introns and synthesis and how to do randomized clinical trials lipid nanoparticles and proline substitution and we did it!
After a brief introduction to cartograms, it shows rolling seven-day average COVID-19 case counts by county, animated by day.
My husband commented that it was easy to see how the suffering moved around. Big dark areas show where there was a lot of suffering. Small dark areas show where there was intense, concentrated suffering.
As I mentioned in my last post, the suffering moved around quite a bit, and that is really easy to see in the video.
I have been working pretty intimately with US COVID19 cases and deaths data for the past six weeks because of my COVID map application, and here are my big takeaways:
It sucks to go first.
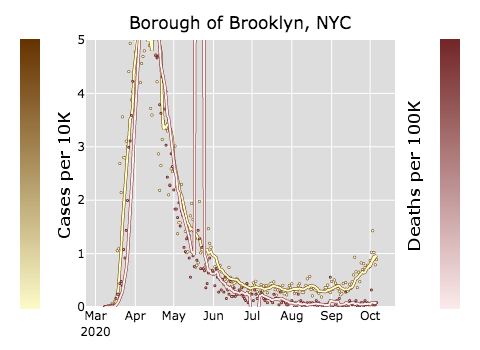
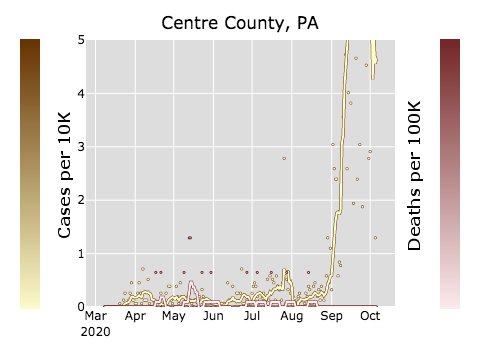
New York and New Orleans got absolutely hammered by COVID early on, and they had a huge number of both cases and deaths. (Yellow is confirmed cases, red is confirmed deaths. Dots are individual days; lines are seven-day rolling averages. Cases are per ten thousand people while deaths are per one hundred thousand people. All of the graphs in this post are at the same scale.)
New York had a huge spike in confirmed cases, followed almost immediately by a huge spike in deaths, so immediately that it’s hard to tell the red line from the yellow line. (I believe that the odd spike in mid-May is due to a reporting issue; about 1500 deaths were reported on that day, but I bet they didn’t happen on that day.)
Note that you need to be a little careful with your interpretation here because there were almost no tests available outside of research labs until mid-March, and very limited tests for quite some time afterwards. The case count is almost certainly an undercount; there is almost no lag between the case peak and the death peak because people didn’t get diagnosed until they were close to death.
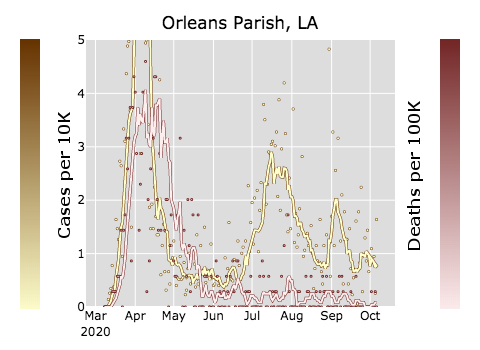
Similarly, New Orlean’s first spike was followed almost immediately by a huge spike in deaths. But look at the later two spikes: deaths did not jump significantly after the later two spikes.
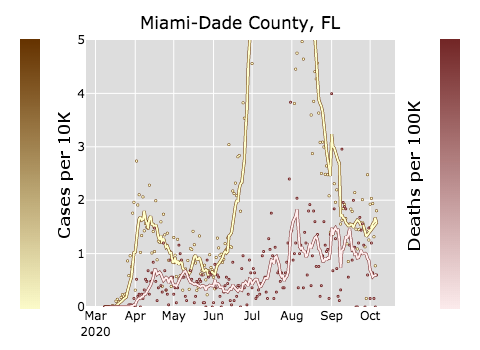
I see this over and over. For example, Miami got hit very hard in July:
While Miami did see an increase in deaths, it was not nearly as bad as the deaths New York and Miami saw in April.
The virus has mutated and gotten less deadly. The article above says that genetic studies do not bear that out, but doesn’t give any more details.
More testing. While it is true that more testing makes the case count higher, that isn’t a big enough effect to account for the numbers.
The virus is hitting younger people. Another way to look at it might be “we have learned how to protect nursing homes”. I don’t have enough data to be able to tell how big a factor that is.
More people have (at least limited) immunity due to prior non-COVID19 corona virus infections. (Many “common cold” viruses are coronaviruses.) I don’t think that would explain it, unless you think that people in New Orleans didn’t have colds before March but did later on.
We are better at treating the disease. This is certainly true. Giving steroids at the right time appears to be significantly better than not.
People are getting infected lower doses of virus and hence are not getting as sick. This also appears to be the case. The viral load of people showing up at hospitals has been dropping, according to the Washington Post article. This is almost certainly due to people wearing masks, standing six feet apart, avoiding restaurants, etc.
The virus moves.
COVID-19 hotspots move around. First, it was New York.
13 April 2020
(This is a cartogram, where counties’ areas are proportional to their population. Big regions mean cities; small regions are rural. Yellow is good, brown is bad.)
In the summer the Sunbelt got hit.
26 July 2020
Currently, the hotspots are in the northern central-west US — Wisconsin, Wyoming, Montana, Utah, etc., and scattered rural areas.
1 October 2020
There are very few places where the virus has not gotten to — yet. Places that have had outbreaks, particularly which have had nasty outbreaks (I’m looking at you, Northeast), are mostly doing a good job of managing now.
It almost seems like places aren’t able to learn from everyone else’s misery, they need to have a nasty outbreak themselves to truly believe that it can happen to them.
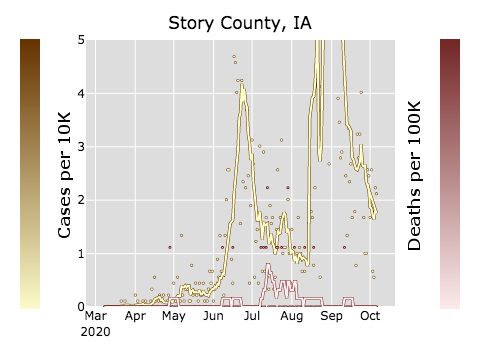
Reopening universities in person was a bad idea.
Cases spiked in early September in college towns:
Home of the University of Illinois
Home of the University of Iowa
Home of Indiana University
Home of the University of Missouri
Home of the University of Pennsylvania
Go VT, NH, ME, PA!
The far northeastern states have done an outstanding job, with almost no cases — yet.
Aside from some minor outbreaks early on and an outbreak right now in Centre County — which is almost certainly due to Penn State University reopening (see above) — Pennsylvania has done a really good job — so far.
Western Oregon and Western Washington have also done a good job — so far. Colorado has mostly done a good job — so far.
I’m studying Italian, and decided to have some fun with alliteration for a recent assignment:
If you don’t cheat, we will take care of you: Se si non bara, baderemo a voi.
They released the libertine books: Si sono liberati i libri libertini.
Everyone was fascinated by the fascist booklets: Tutti affascina dai fascicoli fascisti.
Wealthy Rocky was remembered: Si è ricordato ricco Rocco.
If you find yourself in a scuffle at a gambling den, don’t give an encore: Quando ci si trova in una rissa nella bisca, non si bissa.
You need to put the painting on the easel in order to paint the pony eating the cabbage: Si deve mettere il quadro sul cavalletto in modo di dipingere il cavallino mangiando il cavolo.
The high-level students were relieved by lifting the veil of work: Si alleviano gli allievi di un elevato livello levando il velo dal lavorare.
In prison, Charles blew up limestone and loaded the cart before going to bed: Nel carcere, Carlo fa scoppiare il calcare e carica il carrello prima di coricarsi.
Afterwards, the dust was raining a bit upon the poor octopus: Poi, la polvere pioveva un po’ sulla povera piovra.
This probably doesn’t compare to a master’s French Onion soup, with the onions lovingly caramelized in a wine sauce for 40 minutes over the perfect amount of heat. However, it is a lot easier and still really tasty.
Get a bunch of onions — as many as will fit in your oven-safe pot — and take the skins off and that nasty stringy thing at the bottom of the onion. No need to chop the onions up (yet), except to trim as needed to make them all fit into your pot.
Put the onions in the afore-mentioned oven-safe pot. I use a 5.3 litre dutch oven, which holds about nine big onions.
Toss the pot+onions in the oven for three hours at 375F. (I put a lid on my dutch oven; the guy who taught me the trick about caramelizing leaves the lid off and cooks at 300F.) When the three hours are up, just leave them in the oven to cool down. (The oven will have sterilized everything; if you don’t open the door, you ought to be able to leave them in there safely for quite a long time.) I tend to let them cool for two or three hours because I am lazy and also tend to forget about them.
After the onions have cooled, pull them out of the oven and chop them up into bite-sized pieces. (Note that because the onions are now cooked, you can chop them up without any concern about onion tears!)
Put the onions back into the dutch oven and put in enough bouillon/stock to cover them. (I use Better Than Bouillon brand goo. I love that stuff.)
Add thyme, black pepper, and white pepper.
With my 5.3L Dutch oven, I use these amounts:
1 teaspoon thyme
20-40 turns of my black pepper grinder, which I think is between .75 and 1.5 teaspoons.
20-40 turns of my white pepper grinder, which I think is between .5 and 1 teaspoon
This recipe is very forgiving: a wide range of pepper amounts will be yummy.
Note that I do not add any salt. Most bouillons have enough salt in them already. If you are using home-made soup stock, you might want to add salt.
Heat the wet mixture up. You don’t need to cook it for a long time, you’re just getting the spices mixed in and getting the liquid warm.
Meanwhile, haul out something which is broiler-safe and single-serving sized. We have this soup often enough that we bought specialized French Onion Soup bowls, but ramekins work also.
For each of your bowls, cut a piece of bread to fit the bowl, and cut your favourite cheese to cover the bread. (The canonical French Onion Soup cheese is Gruyere, but me, I prefer cheddar.)
When the wet mixture is warm, put it in your oven safe bowl, float the bread on top of the liquid, and put the cheese on top of the bread.
Take your bowls and put them on a cookie sheet (to catch any spills). Set your oven to broil and put the bowls plus cookie sheet in the oven.
Leave the oven door open a crack. Two reasons: 1) the range manual says to and 2) then you can see when they are done.
Watch. The cheese will melt and bubble and eventually turn golden. When you see just a little bit of brown, you should pull the bowls out. A little bit of singeing is okay, but you don’t want it to burn. This takes about five minutes.
Serve right away. Be careful, the bowls will be HOT!
I’m low class, I like to use a knife to cut up the bread and cheese on the top. (My husband is classier and manages to use only a spoon.) Have a piece of bread handy to clean the bowl with at the end, as you’ll have little yummy bits left.
This recipe and a 5.3L Dutch oven yields a LOT of liquid — maybe enough for ten bowls of soup? The good news is that the wet mixture stores nicely in either the freezer or the fridge. Put it in the oven safe bowls, toss it in the microwave to heat it up a bit, add bread and cheese, then put it in the broiler. (If you put it in the broiler without heating the liquid first, the liquid will be unsatisfyingly tepid.)