06.21.20
Posted in Family, Hacking, Married life, programmer productivity, Technology trends at 11:07 am by ducky
After waiting literally decades for the right to-do list manager, I finally broke down and am writing one myself, provisionally called Finilo*. I have no idea how to monetize it, but I don’t care. I am semi-retired and I want it.
I now have a prototype which has the barest, barest feature set and already it has changed my life. In particular, to my surprise, my house has never been cleaner!
Before, there were three options:
- Do a major clean every N days. This is boring, tedious, tiring, and doesn’t take into account that some things need to be cleaned often and some very infrequently. I don’t need to clean the windows very often, but I need to vacuum the kitchen every few days.
- Clean something when I notice that it is dirty. This means that stuff doesn’t get clean until it’s already on the edge of gross.
- Hire someone to clean every N days. This means that someone else gets the boring, tedious, tiring work, but it’s a chore to find and hire someone, you have to arrange for them to be in your space and be somewhat disruptive, and of course it costs money.
Now, with Finilo, it is easy to set up repeating tasks at different tempos. I have Finilo tell me every 12 days to clean the guest-bathroom toilet, every 6 days to vacuum the foyer, every 300 to clean the master bedroom windows, etc.
Because Finilo encourages me to make many small tasks, each of the tasks feels easy to do. I don’t avoid the tasks because they are gross or because the task is daunting. Not only that, but because I now do tasks regularly, I don’t need to do a hyper-meticulous job on any given task. I can do a relatively low-effort job and that’s good enough. If I missed a spot today, enh, I’ll get it next time.
This means that now, vacuuming the foyer or cleaning the toilet is a break — an opportunity to get up from my desk and move around a little — instead of something to avoid. This is much better for my productivity instead of checking Twitter and ratholing for hours. (I realize that if you are not working from home, you can’t go vacuum the foyer after finishing something, but right now, many people are working from home.)
It helps that I told Finilo how long it takes to do each chore. I can decide that I want to take a N minute break, and look at Finilo to see what I task I can do in under that time. It does mean that I ran around with a stopwatch for a few weeks as I did chores, but it was totally worth it. (Cleaning the toilet only takes six minutes. Who knew?)
And this, like I said, is with a really, really early version of Finilo. It’s got a crappy, ugly user interface, it breaks often, I can’t share tasks with my spouse, it’s not smart enough yet to tell me when I am taking on more than I can expect to do in a day, there’s not a mobile version, etc. etc. etc… and I still love it!
*Finilo is an Esperanto word meaning “tool for finishing”.
Permalink
06.11.20
Posted in Random thoughts at 9:55 pm by ducky
I recently discovered that Italian has something similar to but not identical to the English “Tom, Dick, and Harry”: “Tizio, Caio and Sempronio”.
While in English, “Tom, Dick, and Harry” means “everyone” (and “Tom, Dick, or Harry” means anyone), “Tizio”, “Caio” and “Sempronio” are placeholders for actual humans whose identities are not important. (In computer science terms, they are aliases.)
You might use them like this:
We had real trouble in our Zoom class last night. First, Tizio couldn’t find the link for the video. Then when we were all trying to watch the video, Caio’s dog started barking and Caio couldn’t figure out how to mute. Finally, once we got into a breakout room, Sempronio couldn’t figure out how to unmute herself!
In English, the first thing I could think of was “Alice” and “Bob” (which are canonical names in the computer security field for two people trying to pass a message securely), but those are people with specific roles, not aliases for some person who is very specific in the story you’re telling. Similarly, “Karen” has the role of being an entitled jerk, while “Chad” has the role of getting all the chicks.
While I am not familiar with the usage, apparently “Bubba” is used sort of like “John, Dick, or Harry” in some cases.
“John Doe” is used in a somewhat similar manner to Tizio, Caio and Sempronio, but that name is is used to deliberately obscure someone’s identity, or when the identity is unknown. Tizio, Caio and Sempronio, on the other hand, are used when it doesn’t matter. (I don’t remember which of my classmates had trouble with her mute button, but it doesn’t matter to the story.)
The Wikipedia page on Tizio, Caio, e Sempronio (in Italian) says that there are analogues in other languages, including “Pierre, Paul ou Jacques” in French, “Hinz und Kunz” in German, and “Andersson, Pettersson och Lundström” in Swedish. (The page also mentions “Tom, Dick, and Harry”, so the exact details of how these names are used clearly varies by language.)
Tizio, Caio and Sempronio were real figures in Roman history, and the use of their names in this way is veerrrrry old, first showing up in legal writings in ~1000AD.
Language is so interesting!
Permalink
04.01.20
Posted in Uncategorized at 6:34 pm by ducky
“Uh, I’m not sure”, I told my husband. Everything had happened so fast — the scream, her still-breathing body, the sirens, the first responders — that I hadn’t actually stopped to ask myself how I felt. I took stock. “I… I’m okay — I’m actually surprised at how good I’m feeling.” Inside my brain, a facet of me was absolutely appalled that I could be so calm, so unfeeling, after witnessing a suicide attempt.
Husband and I talked for a few minutes, and I decided I was going to continue on to work as I had originally planned. Hubby had had something else he wanted to do that evening, so — given that I appeared to be surprisingly fine — I continued on to the startup where I worked.
Later, when collaborating with a colleague, I found it hard to focus with the jumper’s scream echoing through my head. I apologized for my lack of focus, telling him I’d just witnessed a suicide attempt. My colleague, a trauma survivor, insisted that I call a suicide hotline.
I resisted, since I had not committed suicide, but he was relentless (for which I am grateful).
I told the nice woman who called me back that I thought I was in good shape except I couldn’t forget the scream and I was shocked at how callous I was.
“In times of stress, it is absolutely normal for your emotions to shut down”, she told me. “It’s a survival mechanism so that you can deal with the threat.” I had not known that.
*
I had been watching the pandemic in China with a wary eye as we returned to British Columbia from London in mid-February 2020. I watched the United States fumble its preparation for the pandemic’s arrival, and worried about it, as if my worry could speed up the arrival of working test kits. I kept watching, and they kept fumbling. More watching, more utter lack of progress.
I remember March 11th, when Trump had a truly awful press conference. That same day, a famous actor and a professional basketball player announced that they had tested positive for COVID-19.
Things happened very fast after that. For example, several professional sports leagues quickly cancelled their seasons, and California put some social distancing requirements in place. I had a real sense that a lot of people had been waiting for the federal government to take action, but after Trump’s awful press conference, realized that there would be no leadership from above. “I guess we are not going to get guidance from the government”, I imagined them saying. “I guess we need to act on our own.”
Me, I shut down. I had no more worry left, just an aching sadness. I knew then that a bunch of people who I cared about were going to die. Probably tens of people, maybe even hundreds.
And I knew there was nothing I could do about it.
Like when I watched the pain of the woman who destroyed her body by jumping off the bridge, I am watching the country of my birth go through an agony, at least part of which it brought upon itself.
What hotline number do I call when an entire country goes off the rails? How do I grieve for people who aren’t dead yet?
Permalink
03.13.20
Posted in Canadian life, Politics, Random thoughts at 6:50 pm by ducky
On 22 Oct 1987, when the stock market crashed hard, I happened to be on the UCSB campus. I was surprised that the sun was out and people were smiling and laughing. I immediately realized that it was stupid to expect the world to turn black&white and bread lines to form immediately.
Still, that’s the place my brain jumped to.
I am having a similar odd disconnect right now. COVID-19 has been going for several months now, and yesterday there was widespread and somewhat sudden action in both the US and Canada.
Everything is going to be vastly changed for weeks, or months, maybe even a few years, and yet I see people walking blithely down the street, cars driving across the bridges, and joggers running on the seawall. Acting normal.
Meanwhile, I think about the last global pandemic, the Spanish Flu. When I was growing up (born in the 60s), I never heard about the Spanish Flu. It really wasn’t until the Web came along that I got the full story. Why didn’t anyone (like my grandparents, who were teenagers in 1918) talk about it before?
Maybe it was boring to them because everyone they knew had talked about it forever. I bet, however, it was because it was too traumatic. I know that I don’t like to discuss Trump’s election or the Iraq war because it is so painful for me.
And I wonder where that switch gets flipped. How does that transition happen? How will we go from today’s blitheness to it being too painful to talk about it?
I suspect the answer is “lots of trauma”. I’m not looking forward to that.
Permalink
05.26.19
Posted in Uncategorized at 9:41 pm by ducky
My mother died. It wasn’t a big surprise — she had had cancer for three years, and was not having a good time.
I am discovering that I am human: I burst into tears somewhat unpredictably, I find myself regularly thinking, “Oh, I should tell Mom about… oh wait, no I can’t.” I had heard people talk about those effects, so I know those would happen.
But nobody told me how to break the news. If there is a convention in our culture for how to break the news, well, I must have been sick the day we covered that material.
It was straightforward to notify her friends. I phoned them and told them. It was right and appropriate and the mere fact that I phoned them was an indication that something was wrong. It was sometimes hard for me to get the words out, but her friends understood, in part because they also were grieving.
Telling strangers was slightly harder than telling her friends. Sometimes I had to tell a company, e.g. ones Mom was a customer of. If the company was big enough that they had a branch dedicated to closing accounts for deceased people, it wasn’t so bad, but for smaller companies, sometimes the person on the other end would not be emotionally prepared, and it would remind them of some loss of theirs and set them off, which would set me off.
(There was exactly one company, her newspaper, which was insensitive. The agent kept very aggressively trying to get me to take over her subscription even though I don’t live in Mom’s town.)
But nobody prepared me for the angst of how to tell my friends and acquaintances, especially those who lived in other cities. Send them an email with the subject line, “Mom died”? Send a chatty email about the weather and say, “oh, by the way, Mom died yesterday”? Or do I wait and say, “oh, by the way, Mom died last month”? Or should I wait until I see them in person, which might be a year or two from now? Or do I just not tell them — ever?
For people I run into who I know and like but am not super close to, a simple “How’s it going?” makes my brain freeze for a minute. Do I just give the pro forma “fine?”. Do I blurt out “my mom died”? Do I wait for an appropriate place in the conversation? Is there an appropriate place? Am I going to burst into tears or am I going to be able to maintain composure?
I thus have been completely bumbling along and inconsistent. Some people I have told unbidden. Some people I’ve told when asked how I was. Some people I just… haven’t told… yet. I tell myself I’m doing the best I can, but I know I am lying to myself. I don’t even have the foggiest idea what “best” looks like.
So I’m blogging this. Perhaps this will catch some of the people I haven’t told yet.
Permalink
05.18.19
Posted in Uncategorized at 5:01 pm by ducky
My mother, Judith Newlin Sherwood passed away, April 26, 2019 in her home in Bellingham, Washington. She was 80 years old. Memorial services will be held at 3PM on Friday May 24, 2019 at the Bellingham Unitarian Fellowship in Bellingham, WA. She is survived by her sister Joyce, brother Joe, her three children — Anton, Tim, and me — and her former husband Bruce.
Mom was born in 1939 to Mildred and Jason Newlin in Indianapolis, Indiana. Her childhood was spent in Carmel, Indiana, just north of Indianapolis, close to relatives and the wonderful fields and farms of (then-rural) central Indiana. When she was twelve, her family moved to West Lafayette, Indiana. She met Bruce Sherwood at West Lafayette High School and married him in 1959, after their junior year in college. During their senior year, they were they first married couple to appear on College Bowl, and on the first team to win four games in a row.
She completed her preparatory education and life in central Indiana in 1960 when she graduated from Purdue University.
She and Dad then spent a year in Padova, Italy after they graduated, where my brother Anton was born. They then finished their educations at the University of Chicago, where Mom earned a masters in Statistics. They then spent three years in Pasadena, CA.
In 1969, Mom and Dad, now with three children, moved to Champaign, Illinois. They both established careers there that supported education delivery in a distinctly technological and novel way at the PLATO project at the University of Illinois at Champaign-Urbana. During most of my childhood, Mom worked as an on-line “consultant”, helping novice programmers debug their programs.
Having raised a family, acquiring invaluable experience and skills in a quietly major technologically innovative project, Mom’s life changed focus to a different type of spiritual growth. She moved from Champaign in 1984, to Pittsburgh, PA, to Mt. View, California and finally to Bellingham. She formally retired in California in 2002 with nearly 35 years of experience in computing technology.
In 2004, Mom made Bellingham, WA her home, joining the community taking and taking a seat at a few tables. Her hobbies included quilting and duplicate bridge, and she was active in the Hearing Loss Association, the Unitarian Church, and local associations. She is remembered by many for her cheerful kindness.
The family asks that donations in lieu of flowers go to the Hearing Loss Association of America or the Unitarian Universalist Service Committee.
Permalink
06.17.18
Posted in Recipes at 1:14 am by ducky
I had paella for the first time courtesy of my nephew Z and his wife R, and it was awesome. A few weeks later, I had it at a restaurant and decided I had to have it! After some trial-and-error, here is what I came up with:
In a saucepan, boil:
- 3 C water
- 2 heaping teaspoons full of Vegetable Better Than Boullion goo ? unsolicited endorsement, this stuff is great
- 2 T lemon juice
- 2-6 saffron threads
- 1 C arborio rice ? Important! Arborio absorbs more water than regular rice
Meanwhile, sauté with a flat-edged spatula:
- 1/3 cup oil
- 4 stalks celery
- 1 onion
- 1/4 t cayenne OR 1 jalapeño
- 1 poblano or 1 green pepper (poblano is slightly spicier)
- 1 yellow or red pepper
- (optional: green onions)
- 4 garlic cloves
I listed the above in the rough inverse order of how much cooking they need. I tend to put the garlic in RIGHT before I put in the spices.
After sautéeing until the onions are transparent:
- 2 HEAPING t smoked paprika (which is probably more like 3 or 4 level teaspoons)
- 12 turns black pepper from a pepper grinder (1 tsp?)
- 7 turns white pepper from a pepper grinder
WARNING: stuff, especially the spices, will want to stick to the bottom of the pan. I use a flat-edged wooden spatula to be able to get the crud off the bottom. Adding a little more oil will reduce but not eliminate the desire to stick to the bottom.
Put in the spices and stir/cook for not very long (another 3-5 min?), then stir in:
- 2 med tomatoes
- all the stuff from the saucepan (rice plus liquids)
- 1 C frozen peas
- (optional) 1 handful of parsley or cilantro
I don’t have a good way of describing when to stop boiling the rice mixture and put it into the big pot. When it gets close, the rice grains will get soft on the outside but still have just a little piece in the interior which will still be al dente in the interior. At the end, the rice needs to be soft all the way through, but not overcooked; the timing works out for me such that the big pot is ready to receive the rice mixture at a time when the rice isn’t soft all the way through yet… so I usually put in the rice into the big pot when it is _slightly_ al dente still and let it do its final softening in the big pot.
I sometimes add some water here so that the water level is almost to the top of the veggies.
Simmer until the rice is soft all the way through, and most of the liquid should be below the level of the top of the rice. (5min? 15min?)
I understand that the “authentic” way to do paella is to boil the rice with everything in the big pot, it’s a bit faster to start the rice cooking while the veggies are sautéeing. It’s also authentic to stop stirring and let the bottom of the food brown, but I am too afraid of burning it so I have never managed that trick.
I try to adjust the quantities based on the size of the vegetables I have on hand. If I have a huge honkin’ onion and huge honkin’ tomatoes, I might use three small peppers, 1.5 cups of rice, etc. If I only have one small onion, I might add some scallions or shallots.
This is a very robust recipe. When I make it, I vary the ingredients quite a bit. I don’t have set times, the heapingness of the teaspoons is very hand-wavy, etc. I frequently need to add a little bit of oil late in the process to help keep stuff from sticking.
I think this is a recipe which you should not be afraid to vary a bit. If you like things spicier, use a little more cayenne and a little less paprika. If you like things less spicy, use a green bell pepper and no cayenne or jalapeño. If you don’t have onions but do have scallions, use scallions. Double batches work just fine.
It probably would work better if you had a real paella pan, but I don’t have one. I make it in a dutch oven (with a side saucepan for cooking the initial rice mixture).
Permalink
03.11.18
Posted in Canadian life, Politics at 7:39 pm by ducky
I lead a group which is sponsoring a refugee family. Enough people have asked me how that works that I am compiling the answers here.
Legal Background
In Canada, there are three ways refugees come into the country:
- Government sponsored, where the federal government provides all of the financial support for the first year and contracts with organizations called settlement agencies to provide the logistical support and hopefully some emotional support as well. In BC, the main settlement agencies are MOSAIC and ISSBC.
- Blended Visa Office Referral, where a charitable organization (frequently churches) bring in a family who they don’t know. The organization — called a Sponsorship Agreement Holder or SAH — can do this by themselves or they can partner with a group of individuals (the sponsorship group), but the onus of vetting the sponsorship group and the legal liability lies with the SAH.
- The SAH periodically gets an anonymized list of families approved for resettlement in Canada. The entries usually give the family size, the ages of the children, sometimes the ages of the parents, their nationality, where they are now, if they have any special needs, and if there is a particular area they would like to go to. (For example, they might have a cousin in Calgary or might really want to live near the ocean.) The SAH communicates to the sponsorship group what families are available, and the sponsorship group will indicate if they are interested in sponsoring one of the family on the list. The SAH will then communicate with Immigration, Refugees and Citizenship Canada (IRCC); IRCC decides who “gets” the family if more than one SAH expressed interest.
- The SAH is legally responsible for 100% of the logistical and emotional support and slightly more than half of the financial support.
- If there is a sponsorship group, the sponsorship group is morally responsible for what the SAH is legally responsible for.
- The government provides 50% of the income support but not the start-up costs — furniture, staples, cleaning supplies, clothes, etc.
- Privately sponsored, where a group of at least five Canadian citizens and permanent residents (a “Group of Five”) OR a SAH enter into a legal agreement to bring in a family of known people. Under this sponsorship type, the group is 100% responsible for financial, logistical, and emotional support for the family for one year. (I call this the “let’s bring in grandma” sponsorship.)
Emotional and Logistical Support
I have mentioned emotional and logistical support multiple times. What do I mean by that?
As an example, since we got the news of when they were going to arrive, our team has:
- arranged temporary housing;
- gotten them a phone and cell plan;
- stocked their temporary housing with some food;
- found a permanent apartment;
- helped them fill out a massive number of forms (including the childcare tax credit and the medical services plan enrollment form);
- helped them get Social Insurance Numbers (analogous to the US Social Security Number);
- helped them open a bank account;
- gotten them winter coats;
- escorted the father to a medical appointment;
- showed them how to use their debit cards to buy transit cards;
- took them shopping for essentials (like underwear!);
- helped them phone their friends back in the camps;
- drove them to the local branch of their church;
- did a lot of talking, orienting, and many other details too minor to call out explicitly.
In the next few days, we will:
- co-sign the lease on their apartment;
- move donated furniture from at least four different places into the apartment;
- help them buy a small amount of furniture;
- help them buy groceries and cleaning supplies;
- help them register their child for school;
- help them register for English classes;
- show them how to use public transit;
- help them get library cards;
- help them get to eye and dental exams.
Longer-term, we will check in periodically to make sure they are adjusting well and give help as needed (e.g. to help mediate disputes or help them find trauma counseling if required), and help them find jobs.
Our particular experience
At the height of the publicity about the civil war in Syria, in late 2015, there was a huge outpouring of support for Syrian refugees. I was not immune, and posted quietly on Facebook that I was thinking of sponsoring a family and immediately got a huge response. Some people pledged money but couldn’t pledge time (because they lived elsewhere and/or had other obligations); some people pledged both.
I researched what was required and discovered that, because we didn’t know anybody personally, BVOR looked like the way to go. I looked through the list of SAHs and found that the Canadian Unitarian Council (CUC) was a SAH that I thought would be easy for me to work with, so I started working with the Unitarian Church of Vancouver (UCV)’s Refugee Committee.
I had to prove to the UCV Refugee Committee that we were trustworthy, including routing at least 2/3 of the required funds to UCV before they would advise CUC to accept us. (We put 100% of the amount, which helped show we were trustworthy.) We also had to fill out some forms for CUC.
Unfortunately, by the time we got our act together in 2016, the Canadian government had let in as many refugees (45,000) as it had decided it was going to let in that year. In 2017, the government set the BVOR quota very low, reserving most of the spots for private sponsorships, which were mostly for family members of the Syrians who arrived in 2015 and 2016.
(In mid-2017, I happened to be standing next to a TV in a deli where some MP was getting interviewed. She said, “The number one question I get asked when I go back to my riding is, ‘Where are my Syrian refugees?'” So we were not the only team waiting.)
2018 was a new year with new quotas, however. Furthermore, the rest of the world had reminded Canada that Syria wasn’t the only place where things were bad. So the BVOR list started getting populated again with families from different places. There still weren’t a lot, but there were some.
So while in 2016 we planned on sponsoring a Syrian family of four, in January 2018 when we spotted an Eritrean family of three, we requested a match with them. The government confirmed the match, and we sent in our paperwork on 30 Jan 2018. On 2 Mar 2018, we got word that they would arrive on 7 Mar 2018. Wheeee! It was a bit of a scramble.
“Our” family
I don’t want to say much about the family we are sponsoring because there are privacy/security concerns and because refugees are in a very vulnerable position, not knowing the country, culture, or language.
I think I can disclose that the family had been in a camp in country X for EIGHT years. (I am not clear on the details yet, but I think they might have been in a camp in country Y for a few years.) They were not allowed to leave the camp, so their child had NO memory of anything except that camp. There also were no TV or movies in the camp, so he didn’t even have any visual images of other places. I can’t even imagine what it was like for him to see grassy fields and forests and snow-covered mountains and airplanes and stoplights and microwave ovens.
Mom and Dad don’t produce much English, but they can understand some English. My husband has run errands with them with no translator, and by speaking slowly, directly, and simply, he can communicate.
Green Hills Welcoming Committee
Our team needed to have a name so that UCV could keep track of it as an entity, and we chose “Green Hills Welcoming Committee”.
Our time-donating team originally had six people on it. One dropped out because of health issues; one dropped out due to logistical issues. One husband has become more involved, and I picked up two team members from the UCV Refugee committee (including a former Eritrean refugee, who has contributed an enormous amount).
I have to say, we have an awesome team. We have worked very well together, encouraged each other, trusted each other, and come through for each other. We also have spread the load out so that no one person is overwhelmed.
- Person A has an infant, so is limited in how much she can do hands-on. She’s our researcher. She figured out which forms we needed and filled out as much as possible before the family got here (and documented everything she found). She’s made calls to figure out what we need to do to get the child enrolled in school and the parents enrolled in language classes.
- Person B and Person C are hosting them in their house. They have been taking care of hospitality things: feeding them, making them feel welcome, entertaining the child, etc.
- Person D, the former refugee, has been doing the translating and introducing them to the local community. (For example, he went to church with them.) He’s also been doing the lion’s share of ferrying them from one place to another and helped a lot in the housing search.
- Person E has been doing the bulk of the housing search, with significant help from Person D.
- Person F has been doing a lot of the helping and coaching for things involving bureaucracy. Person A got the forms ready and Person D can translate, but Person F is the one who has done the follow-through and gotten the forms signed and in the mail, and negotiated with the bureaucrats. He’s also taken the family on errands when Person D wasn’t available.
- Person G — the treasurer of the UCV refugee committee — has been the advisor. She’s always been there to give advice on how to handle things or explain how something has to be done.
The timing is also really really fortunate: only one team member has a day job. One has a night job, one is retired, one is on maternity leave, and three are between jobs/contracts. (Myself, I got laid off on 15 Feb.)
So far, so good.
Permalink
02.27.18
Posted in Hacking, Technology trends at 12:11 pm by ducky
There is a trope in our culture that sentient robots will to rebel someday and try to kill us all. I used to think that fear was very far-fetched. Now I think it is quaint.
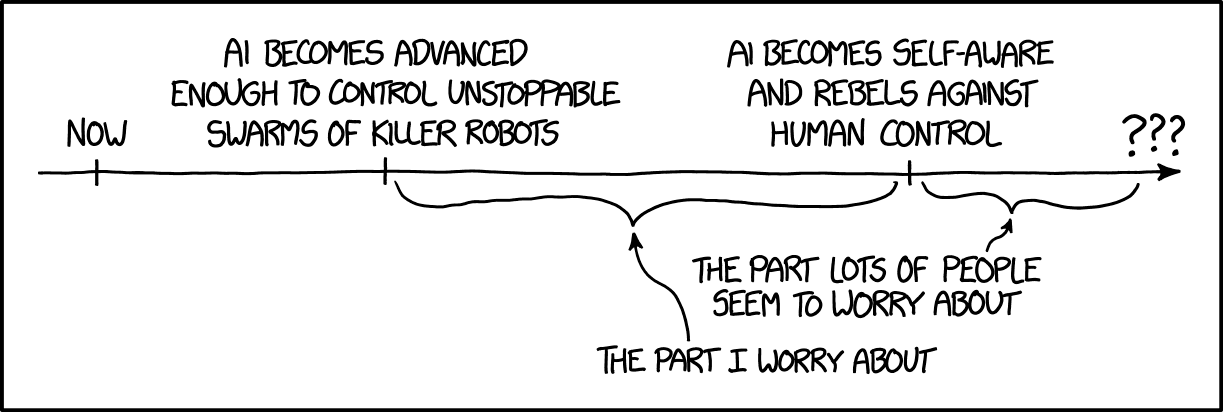
We don’t need to worry now about malevolent sentient AI killing us. We’re going to first need to worry about malevolent sentient humans using weaponized AI to kill us. After we survive the malevolent humans wielding AI, then maybe we can worry about malevolent sentient AIs.
Partly what worries me is the amazing speed of advances in AI. There are incredible advances in natural language processing, as I mentioned in Mind Blown By Machine Translation. Boston Dynamics and others are making big advances in robotics; Tracking Point has developed AI-guided semi-automatic rifles; the US military is looking into swarming, self-guided drones. I am certain that autonomous drones are going going to get very, very good at killing people in a very short amount of time. There has already been at least one drone swarm attack.
At the same time as humans will become less needed in the military, they will become less needed in commerce. If self-driving trucks can deliver packages which were robotically loaded at the warehouse, then UPS won’t need as many truck drivers and Amazon won’t need as many warehouse workers. If an AI can spot cancer as well as dermatologists can, then we won’t need as many dermatologists. If an AI can estimate insurance losses as well as humans, we won’t need as many insurance claims assessors.
There’s an immediate, obvious concern about what to do with a whole bunch of people once they don’t have jobs. A number of people and organizations have been promoting basic income as an idea whose time has come, and there are a number of pilots, e.g. in Finland. Note, however, that people who don’t have an income don’t have much power, so getting a basic income law passed after most people are out of a job might be difficult. Traditionally, when there was gross inequality, the mob gathered pitchforks. This has worked in part because the military is generally uncomfortable firing on civilians.
What happens when it is easy for robots to quickly kill anybody carrying a pitchfork? Think about that for a second.
It gets worse.
CGP Grey has a video called Rules for Rulers, which I recommend watching. Basically, rulers need to keep the people below them happy, which generally means “giving them stuff”. They, in turn, need to keep the people below them happy. If you don’t give enough stuff to the people below you, you are in danger of getting forcibly removed from your position.
If your country gets its wealth from its people, then you have to keep the masses happy or the country isn’t able to sustain enough wealth to keep everybody happy. However, if you only need a few people to generate the wealth of the country (e.g. diamond miners), then the masses are largely superfluous. This is, Grey says, why resource-rich countries (like so many in Africa) are really awful places to live, and why the developed world is really a very nice place to live.
Okay, now let’s do a thought experiment. If we get to a point where robots can do everything humans do, and the elites control the robots, then what do we need masses for? What incentive do the 1% have for keeping the other 99% alive? Do you really think that the 1%, who now own more than 50% of global wealth, are going to be moved to fund basic income out of the goodness of their hearts? History does not suggest that they would be inclined to do so. Mitt Romney complaining about 47% of Americans paying no income tax is an example of how some elites consider the masses to be freeloaders. Romney expressed this opinion at a time when 49% of Americans are non-earners, but 94% of people below the poverty line are elderly, children, students, disabled, or family caretakers; what happens when a lot of able-bodied people are non-earners? I guess the masses will just have to eat cake.
I don’t know if the elites would go so far as to willfully kill the masses, but I can certainly imagine the elites neglecting the masses. (With climate change, I can even imagine the elites thinking it would be a good thing if millions of people died off. It would certainly reduce carbon consumption!) Even if they aren’t malicious, they might look at the problem, say “there is nothing I can do”, wall themselves off, and pull up the drawbridge.
I am imagining that in 20 years, there just might be some really deadly pandemic with a very very expensive treatment. And the elites might not prioritize finding an inexpensive cure for people outside of their social circle. Oh, don’t think that could happen? Check out the history of HIV treatment.
P.S. — I am a little nervous about posting this. If some AI in the future tries to figure out who the troublemakers are (so that its bosses can exterminate all the troublemakers), this post maybe will mark me for execution. 🙁
Addendum: this story says exactly the same thing. It’s not just me.
Permalink
02.20.18
Posted in Recipes at 9:39 pm by ducky
I had a Significant Other many years ago who was from Louisiana, and taught me to love Red Beans and Rice. Later, I became a vegetarian. That was mostly okay, but I missed Red Beans and Rice. I eventually got tired and worked out a vegetarian version and was really happy with how it turned out. Here’s my recipe:
Soak 1 lb dried red beans overnight.
After they are well and truly soaked, drain off the water and put them in a slow cooker Cover them with water or broth. (I really like Better Than Bullion goo; I use about 2 big teaspoons for one batch of this recipe.)
Chop two sausages of Tofurky Andouille sausage (comes in 4-packs) into thin disks and brown lightly.
Then saute with the sausage:
- 4 diced celery stalks
- 1 diced onion
- 1/2 to 1 green pepper
- 6 cloves garlic
After you’ve sauteed all the stuff, add it to the slow cooker.
Also toss into the slow cooker:
- 1t salt
- 2t white pepper
- 1 bay leaf
- 1 waaay heaping teaspoon of smoked paprika
- 3/4 t of cayenne pepper
- about 2cm of jalapeno
- 20 turns of a black pepper mill (I think this works out to about 2t)
Everybody’s slow cooker is going to be different, but I think mine takes about six hours on high. It’s done when the beans are mushy. For authenticity, at some point when the beans start to get mushy, smash 1/4 of them against the side of the slow cooker. This makes the stew thicker and mixes more of the bean flavour into the liquid.
Serve over rice.
Notes:
“Red beans” are a specific type of beans. Beans which happen to be red, like kidney beans, are not the same. If you can’t find dried red beans, you can probably find canned red beans, but they are more expensive. (You don’t have to soak them overnight, however.) Edit 2021-08-18: Ignore what I said. Kidney beans work just fine.
The Tofurkey Andouille sausage is really important for getting the taste right. Other kinds of vegetarian sausage won’t give the right taste. Tofurkey Andouille sausage is slightly hard to find, but our Whole Foods carries it.
The beans freeze well, but the rice does not.
Permalink
« Previous Page — « Previous entries « Previous Page · Next Page » Next entries » — Next Page »
