11.10.20
Posted in Hacking, programmer productivity at 11:55 am by ducky
As mentioned here and here, there is evidence that generating lots of hypotheses helps find the right answer faster.
Hypotheses are a Liability shows that having a hypothesis can make you less able to discover interesting facts about a data set. Very interesting!
Permalink
06.21.20
Posted in Family, Hacking, Married life, programmer productivity, Technology trends at 11:07 am by ducky
After waiting literally decades for the right to-do list manager, I finally broke down and am writing one myself, provisionally called Finilo*. I have no idea how to monetize it, but I don’t care. I am semi-retired and I want it.
I now have a prototype which has the barest, barest feature set and already it has changed my life. In particular, to my surprise, my house has never been cleaner!
Before, there were three options:
- Do a major clean every N days. This is boring, tedious, tiring, and doesn’t take into account that some things need to be cleaned often and some very infrequently. I don’t need to clean the windows very often, but I need to vacuum the kitchen every few days.
- Clean something when I notice that it is dirty. This means that stuff doesn’t get clean until it’s already on the edge of gross.
- Hire someone to clean every N days. This means that someone else gets the boring, tedious, tiring work, but it’s a chore to find and hire someone, you have to arrange for them to be in your space and be somewhat disruptive, and of course it costs money.
Now, with Finilo, it is easy to set up repeating tasks at different tempos. I have Finilo tell me every 12 days to clean the guest-bathroom toilet, every 6 days to vacuum the foyer, every 300 to clean the master bedroom windows, etc.
Because Finilo encourages me to make many small tasks, each of the tasks feels easy to do. I don’t avoid the tasks because they are gross or because the task is daunting. Not only that, but because I now do tasks regularly, I don’t need to do a hyper-meticulous job on any given task. I can do a relatively low-effort job and that’s good enough. If I missed a spot today, enh, I’ll get it next time.
This means that now, vacuuming the foyer or cleaning the toilet is a break — an opportunity to get up from my desk and move around a little — instead of something to avoid. This is much better for my productivity instead of checking Twitter and ratholing for hours. (I realize that if you are not working from home, you can’t go vacuum the foyer after finishing something, but right now, many people are working from home.)
It helps that I told Finilo how long it takes to do each chore. I can decide that I want to take a N minute break, and look at Finilo to see what I task I can do in under that time. It does mean that I ran around with a stopwatch for a few weeks as I did chores, but it was totally worth it. (Cleaning the toilet only takes six minutes. Who knew?)
And this, like I said, is with a really, really early version of Finilo. It’s got a crappy, ugly user interface, it breaks often, I can’t share tasks with my spouse, it’s not smart enough yet to tell me when I am taking on more than I can expect to do in a day, there’s not a mobile version, etc. etc. etc… and I still love it!
*Finilo is an Esperanto word meaning “tool for finishing”.
Permalink
02.27.18
Posted in Hacking, Technology trends at 12:11 pm by ducky
There is a trope in our culture that sentient robots will to rebel someday and try to kill us all. I used to think that fear was very far-fetched. Now I think it is quaint.
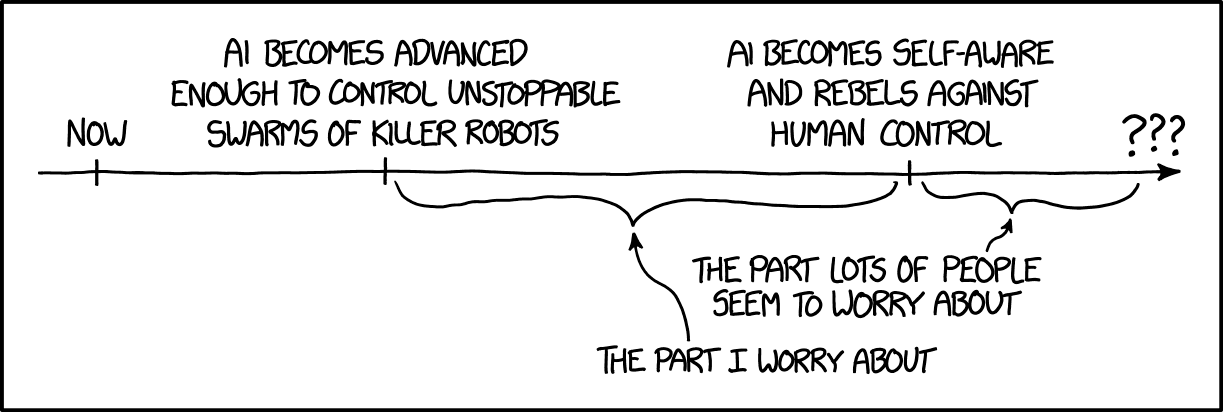
We don’t need to worry now about malevolent sentient AI killing us. We’re going to first need to worry about malevolent sentient humans using weaponized AI to kill us. After we survive the malevolent humans wielding AI, then maybe we can worry about malevolent sentient AIs.
Partly what worries me is the amazing speed of advances in AI. There are incredible advances in natural language processing, as I mentioned in Mind Blown By Machine Translation. Boston Dynamics and others are making big advances in robotics; Tracking Point has developed AI-guided semi-automatic rifles; the US military is looking into swarming, self-guided drones. I am certain that autonomous drones are going going to get very, very good at killing people in a very short amount of time. There has already been at least one drone swarm attack.
At the same time as humans will become less needed in the military, they will become less needed in commerce. If self-driving trucks can deliver packages which were robotically loaded at the warehouse, then UPS won’t need as many truck drivers and Amazon won’t need as many warehouse workers. If an AI can spot cancer as well as dermatologists can, then we won’t need as many dermatologists. If an AI can estimate insurance losses as well as humans, we won’t need as many insurance claims assessors.
There’s an immediate, obvious concern about what to do with a whole bunch of people once they don’t have jobs. A number of people and organizations have been promoting basic income as an idea whose time has come, and there are a number of pilots, e.g. in Finland. Note, however, that people who don’t have an income don’t have much power, so getting a basic income law passed after most people are out of a job might be difficult. Traditionally, when there was gross inequality, the mob gathered pitchforks. This has worked in part because the military is generally uncomfortable firing on civilians.
What happens when it is easy for robots to quickly kill anybody carrying a pitchfork? Think about that for a second.
It gets worse.
CGP Grey has a video called Rules for Rulers, which I recommend watching. Basically, rulers need to keep the people below them happy, which generally means “giving them stuff”. They, in turn, need to keep the people below them happy. If you don’t give enough stuff to the people below you, you are in danger of getting forcibly removed from your position.
If your country gets its wealth from its people, then you have to keep the masses happy or the country isn’t able to sustain enough wealth to keep everybody happy. However, if you only need a few people to generate the wealth of the country (e.g. diamond miners), then the masses are largely superfluous. This is, Grey says, why resource-rich countries (like so many in Africa) are really awful places to live, and why the developed world is really a very nice place to live.
Okay, now let’s do a thought experiment. If we get to a point where robots can do everything humans do, and the elites control the robots, then what do we need masses for? What incentive do the 1% have for keeping the other 99% alive? Do you really think that the 1%, who now own more than 50% of global wealth, are going to be moved to fund basic income out of the goodness of their hearts? History does not suggest that they would be inclined to do so. Mitt Romney complaining about 47% of Americans paying no income tax is an example of how some elites consider the masses to be freeloaders. Romney expressed this opinion at a time when 49% of Americans are non-earners, but 94% of people below the poverty line are elderly, children, students, disabled, or family caretakers; what happens when a lot of able-bodied people are non-earners? I guess the masses will just have to eat cake.
I don’t know if the elites would go so far as to willfully kill the masses, but I can certainly imagine the elites neglecting the masses. (With climate change, I can even imagine the elites thinking it would be a good thing if millions of people died off. It would certainly reduce carbon consumption!) Even if they aren’t malicious, they might look at the problem, say “there is nothing I can do”, wall themselves off, and pull up the drawbridge.
I am imagining that in 20 years, there just might be some really deadly pandemic with a very very expensive treatment. And the elites might not prioritize finding an inexpensive cure for people outside of their social circle. Oh, don’t think that could happen? Check out the history of HIV treatment.
P.S. — I am a little nervous about posting this. If some AI in the future tries to figure out who the troublemakers are (so that its bosses can exterminate all the troublemakers), this post maybe will mark me for execution. 🙁
Addendum: this story says exactly the same thing. It’s not just me.
Permalink
08.16.14
Posted in Hacking, Random thoughts, Technology trends at 5:11 pm by ducky
There are a huge number of to-do list managers (TDLMs) out in the world now, but none of them do what I want. Apparently, it’s not just me: I just read an article which said that when students were asked what mobile apps they really wanted, 20% said they wanted “a comprehensive to-do + calendaring + life management app that helps them better organize their lives”. TWENTY percent!
Is it really that hard?
I have strong opinions about what I want, and I don’t think it’s that hard, so I will describe my desires here in the hopes that somebody will make me the perfect TDLM. (Some of the features you can see in a TDLM which I wrote for a class project. Sometimes I think about writing my perfect TDLM, but I’m busy with other things. I want it to exist, not to write it myself.)
The most important thing is that the TDLM should make you feel better about your tasks. The biggest problem with TDLMs right now is that they make you feel guilty: the list grows and grows and grows because there are an infinite number of things it would be nice to do and only a finite amount of time. This means that every time you open the TDLM, you feel overwhelmed by guilt at all the things you haven’t done yet.
1. Hide stuff you can’t work on right now because of blocking tasks. Don’t show me “paint the bedroom” if I haven’t finished the task of “choose colour for bedroom”. (This means you need UI for showing what tasks depend upon which other tasks, and I warn you that’s not as easy as you think.)
2. Hide stuff you won’t work on right now because you are busy with other things. Don’t show me “paint the bedroom” if I have decided that I’m not going to start that project until I finish doing my taxes. “Do taxes” is not truly a blocking task — it’s not like I am going to use the tax forms to apply the paint — but hide it anyway. (This means you need UI for showing what the sequencing of tasks is.)
3. Hide stuff you won’t work on right now because it is the wrong time of year. Maybe you want a task of “buy new winter jacket”, but you want to wait until the end of winter to get take advantage of the sales on coats. You should to be able to tell your TDLM to hide that task until March. (Or until May, if you live in Manitoba.) Or “rotate tires” is something which only needs to happen every six months.
Note that this implies connecting the TDLM to a calendar, at least minimally.
4. Allow recurring to-do list items. I don’t want to have to make a new task for our wedding anniversary every year. I want to set it once and forget it. Usually people put things on their calendars for repeating events, but “Wedding Anniversary” goes on August 22nd and is not a task. “Plan something for anniversary” is a recurring task but should be hidden until at about August 1st.
The TDLM should distinguish between recurring tasks which expire and those which do not. Non-expiring tasks are ones like “pay phone bill”. Even if you forget to pay it by the due date, you still need to deal with it. On the other hand, “run 2km” is an expiring item: if you couldn’t do your 2km run on Monday, it probably does not mean that you should run 4km on Wednesday.
5. Make me feel super-good about finishing tasks. A lot of TDLMs handle checking something as done by making it disappear. This is the worst. I’ve spent hours, weeks, or months looking at that dang task, and when I finally finish it, I want to savour the moment! I want my TDLM to cheer, to have fireworks explode on the screen, and maybe even have the text of the task writhe in agony as it dies an ugly painful death. I want there to be a display case in my TDLM of things that I have finished recently that I can look at with pride. “Yeah”, I can think, “I am ***DONE*** with painting the bedroom!” Maybe I don’t need full fireworks for a simple, one-step task which took 15 minutes, but if it was a 2000-step task which took 5 years (like getting a PhD or something like that), I want the TDLM to cheer for a full five minutes.
6. Let me see what I did. Sometimes, I feel like I didn’t get anything done, and it is reassuring to look at a list of the things that I actually did accomplish. It might be nice to show it in a horizontal latest-first timeline form:
- 4:47 pm Laundry
- 3:13 pm Groceries
- 12:11 pm Replace laptop display
- (etc)
I would also like to be able to modify the task completion times. “Oh, I actually finished replacing the laptop last night, I just didn’t feel like telling the TDLM because it was late and I was tired.”
7. Let me see what I am going to do. People usually use calendars for this, but as I mentioned before, calendars are kind of the wrong tool. I don’t really want to see “buy birthday present for Mom” in the same place as “Meet with boss, 10:30 AM”. Plus, a strict time-base is makes zero sense if the dependencies are other tasks.
8. Let me import/modify/export task hierarchies. Suppose you want to have a wedding. (Mazel Tov!) There are predictable things which you need to do: book a space for the wedding, a space for the reception, book an officiant, book a caterer, choose a menu, etc. If, say, you want a wedding sort of like your friend Joanne’s, it would be nice if Joanne could email you the hierarchy of tasks that she did for her wedding, and you could just drop it in to your TDLM. (Perhaps that way, you wouldn’t forget to rent a dance floor.)
But maybe you have some Greek heritage and Joanne does not, so you need to add “get a stefana” to your list. You should be able to do that — and then export your new wedding task list for your brother when he gets married. Even better, you ought to be able to upload it to a site which hosts lots of packaged tasks, maybe even a whole section on weddings (so your brother could pick and choose which wedding task list he likes best).
Needless to say, the exported task hierarchy should be in a form which lends itself well to version control and diffing. 🙂
9. Let me collaborate on tasks with other people. I would like to be able to share my “home” tasks with my husband, so that he could assign me tasks like “buy three kitchen sponges”. Ideally, I’d think I’d like to be able to see three task lists: his, mine, and ours.
My husband and I would probably set things up to both have read/write permission on all three — but there are some things that only one of us can or should do. I can imagine other couples might want to not have write permission on each other’s, only on the “ours” one.
10. Make it easy to discuss tasks. This means assigning a simple ID and URL to the task. If Jim and I are going to share tasks, we are going to discuss them. It would be nice to be able to say, “Task #45” instead of “that one about the paintbrushes”. It would also be nice to be able to email a link to him which will take him right to Task #45.
11. (Nice to have) Allow putting a time estimate on the task. If you know that it takes you about two hours to get to your locker, change clothes, stretch, run 2km, stretch, shower, change clothes, and get back to your workplace, then it might be nice to put in an estimate for the “run 2km” task.
If you can put a time estimate on a task and adjust it later, the TDLM could keep track of estimated vs. actual, and start to help you adjust your estimates. “For tasks which you estimate are going to be about 3hrs, you spend an average of 4.15 hrs.”
It would also be nice if the TDLM could help you make estimates based on similar tasks which you completed. When entering an estimate for painting the living room, it would be nice if the TDLM mentioned, off to the side, how long it took you to paint the bathroom and the bedroom. (It’s even okay if it also tells you how long it took you to paint the landscape or your fingernails; presumably you’d be smart enough to figure out which tasks were relevant.)
12. (Nice to have) Make the TDLM geo-aware. It would be kind of nice to be able to hide tasks until I was at or near a particular location. For example, if I am not in a big hurry to paint the bedroom, hide “buy paint” until I am actually at the paint store.
Something requested by the students in the article I mentioned earlier was being told to leave in order to make it to the next appointment. “Doctor’s appointment at 3pm” is a calendar event, but “get to doctor’s office” is a task which needs to happen at a time which depends upon how long it takes to get to the doctor’s office from where you are. That’s another way that geo-awareness could be useful.
13. (Maybe nice to have) Be able to mark urgency. I am not actually certain how useful this is. I have had TDLMs which allowed me to mark urgency, and I found that I almost never used it. I think people will expect it, however.
14. (Nice to have, but difficult) Integrate with my applications. Tasktop Technologies has a product called Tasktop Dev, which kept track of what you did in the source code editor (and some other applications, e.g. web browser and Microsoft Office) while you were working on a specific task. (You had to tell it, “now I am working on task #47” so that it would know to start watching.) Then, there was a record of what you worked on for that task. That was useful if you needed to stop and restart the task (especially over a long period of time), or if you needed to go back a long time later and see what you had done. (“What was the URL of that caterer with the really nice cheesecake?”)
In a work environment, it would be nice to integrate it with other task management systems (AKA “bug trackers”) like Jira or Asana or Bugzilla.
This is what I want. If it persists in not existing, I might have to do it myself someday. (27 July 2020 — I got tired of waiting. I am now developing the perfect to-do list manager, and it has already changed my life.)
Permalink
04.18.13
Posted in Hacking, Maps at 1:20 am by ducky
The Huffington Post made a very nice interactive map of homicides and accidental gun deaths since the shooting at Sandy Hook. It’s a very nice map, but has the (very common problem) that it mostly shows where the population density is high: of course you will have more shootings if there are more people.
I wanted to tease out geographical/political effects from population density effects, so I plotted the gun deaths on a population-based cartogram. Here was my first try. (Click on it to get a bigger image.)

Unfortunately, the Huffington Post data gives the same latitude/longitude for every shooting in the same city. This makes it seem like there are fewer deaths in populated areas than there really are. So for my next pass, I did a relatively simple map where the radius of the dots was proportional to the square root of the number of gun deaths (so that the area of the dot would be proportional to the number of gun deaths).

This also isn’t great. Some of the dots are so big that they obscure other dots, and you can’t tell if all the deaths were in one square block or spread out evenly across an entire county.
For the above map, for New York City, I dug through news articles to find the street address of each shooting and geocoded it (i.e. determined the lat/long of that specific address). You can see that the points in New York City (which is the sort of blobby part of New York State at the south) seem more evenly distributed than for e.g. Baltimore. Had I not done that, there would have been one big red dot centered on Manhattan.
(Side note: It was hugely depressing to read article after article about people’s — usually young men’s — lives getting cut short, usually for stupid, stupid reasons.)
I went through and geocoded many of the cities. I still wasn’t satisfied with how it looked: the size balance between the 1-death and the multiple-death circles looked wrong. It turns out that it is really hard — maybe impossible — to get area equivalence for small dots. The basic problem is that with radiuses are integers, limited by pixels. In order to get the area proportional to gun deaths, you would want the radius to be proportional to the square root of the number of gun deaths, or {1, 1.414, 1.732 2.0, 2.236, 2.449, 2.645, 2.828, 3.000}, the rounded numbers will be {1, 1, 2, 2, 2, 2, 3, 3, 3}; instead of areas of {pi, 2*pi, 3*pi, 4*pi, …}, you get {pi, pi, 4*pi, 4*pi, 4*pi, 9*pi, 9*pi, 9*pi}.
Okay, fine. We can use a trick like anti-aliasing, but for circles: if the square root of the number of gun deaths is between two integer values (e.g. 2.236 is between 2 and 3), draw a solid circle with a radius of the just-smaller integer (for 2.236, use 2), then draw a transparent circle with a radius of the just-higher integer (for 2.236, use 3), with the opacity higher the closer the square root is to the higher number. Sounds great in theory.
In practice, however, things still didn’t look perfect. It turns out that for very small dot sizes, the dots’ approximations to circles is pretty poor. If you actually zoom in and count the pixels, the area in pixels is {5, 13, 37, 57, 89, 118, 165, …} instead of what pi*R^2 would give you, namely {3.1, 12.6, 28.3, 50.3, 78.5, 113.1, 153.9, …}.

But wait, it’s worse: combine the rounding radiuses problem with the problem of approximating circles, and the area in pixels will be {5, 5, 13, 13, 13, 13, 37, 37, 37, …}, for errors of {59.2%, -60.2% -54.0% -74.1% -83.4% -67.3% -76.0%, …}. In other words, the 1-death dot will be too big and the other dots will be too small. Urk.
Using squares is better. You still have the problem of the rounding the radius, but you don’t have the circle approximation problem. So you get areas in pixels of {1, 1, 4, 4, 4, 9, 9, 9, …} instead of {1, 2, 3, 4, 5, 6, 7, 8, …} for errors of {0.0%, -50.0%, 33.3%, 0.0%, -20.0%, -33.3%, 28.6%, …} which is better, but still not great.
Thus: rectangles:

Geocoding provided by GeoCoder.ca
Permalink
03.12.13
Posted in Hacking, Maps at 11:54 am by ducky
In the past, when people asked me how I managed to make map tiles so quickly on my World Wide Webfoot Maps site, I just smiled and said, “Cleverness.” I have decided to publish how I optimized my map tile generation in hopes that others can use these insights to make snappier map services. I give a little background of the problem immediately below; mapping people can skip to the technical details.
Background
Choropleth maps colour jurisdictions based on some attribute of the jurisdiction, like population. They are almost always implemented by overlaying tiles (256×256 pixel PNG images) on some mapping framework (like Google Maps).
 |
| Map tile from a choropleth map (showing 2012 US Presidential voting results by county) |
Most web sites with choropleth maps limit the user: users can’t change the colours, and frequently are restricted to a small set of zoom levels. This is because the tiles are so slow to render that the site developers must render the tile images ahead of time and store them. My mapping framework is so fast that I do not need to pre-render all the tiles for each attribute. I can allow the users to interact with the map, going to arbitrary zoom levels and changing the colour mapping.
Similarly, when people draw points on Google Maps, 100 is considered a lot. People have gone to significant lengths to develop several different techniques for clustering markers. By contrast, my code can draw thousands very quickly.
There are 32,038 ZIP codes in my database, and my framework can show a point for each with ease. For example, these tiles were generated at the time this web page loaded them.
 |
| 32,038 zip codes at zoom level 0 (entire world) |
| |
 |
| Zip codes of the Southeast US at zoom level 4 |
(If the images appeared too fast for you to notice, you can watch the generation here and here. If you get excited, you can change size or colour in the URL to convince yourself that the maps framework renders the tile on the fly.)
Technical Details
The quick summary of what I did to optimize the speed of the map tile generation was to pre-calculate the pixel coordinates, pre-render the geometry and add the colours later, and optimize the database. In more detail:
Note that I do NOT use parallelization or fancy hardware. I don’t do this in the cloud with seventy gajillion servers. When I first wrote my code, I was using a shared server on Dreamhost, with a 32-bit processor and operating system. Dreamhost has since upgraded to 64-bits, but I am still using a shared server.
Calculating pixel locations is expensive and frequent
For most mapping applications, buried in the midst of the most commonly-used loop to render points is a very expensive operation: translating from latitude/longitude to pixel coordinates, which almost always means translating to Mercator projection.
While converting from longitude to the x-coordinate in Mercator is computationally inexpensive, to convert from latitude to y-coordinate using the Mercator projection is quite expensive, especially for something which gets executed over and over and over again.
A spherical mercator translation (which is actually much simpler than the actual projection which Google uses) uses one logarithmic function, one trigonometric function, two multiplications, one addition, and some constants which will probably get optimized away by the compiler:
function lat2y(a) { return 180/Math.PI * Math.log(Math.tan(Math.PI/4+a*(Math.PI/180)/2)); }
(From the Open Street Maps wiki page on the Mercator projection)
Using Lists of instruction latencies, throughputs and micro-operation breakdowns for Intel, AMD and VIA CPUs by Agner Fog, I calculated that a tangent can take between 11 and 190 cycles, and a logarithm can take between 10 and 175 cycles on post-Pentium processors. Adds and multiplies are one cycle each, so converting from latitude to y will take between 24 and 368 cycles (not counting latency). The average of those is almost 200 cycles.
And note that you have to do this every single time you do something with a point. Every. Single. Time.
If you use elliptical Mercator instead of spherical Mercator, it is much worse.
Memory is cheap
I avoid this cost by pre-calculating all of the points’ locations in what I call the Vast Coordinate System (VCS for short). The VCS is essentially a pixel space at Google zoom level 23. (The diameter of the Earth is 12,756,200 meters; at zoom level 23, there are 2^23 tiles, and each tile has 256 or 2^8 pixels, so there are 2^31 pixels around the equator. This means that the pixel resolution of this coordinate system is approximately .6cm at the equator, which should be adequate for most mapping applications.)
Because the common mapping frameworks work in powers of two, to get the pixel coordinate (either x or y) at a given zoom level from a VCS coordinate only requires one right-shift (cost: 1 cycle) to adjust for zoom level and one bitwise AND (cost: 1 cycle) to pick off the lowest eight bits. The astute reader will remember that calculating the Mercator latitude takes, for the average post-Pentium processor, around 100 times as many cycles.
Designing my framework around VCS and the Mercator does make it harder to change the projection, but Mercator won: it is what Google uses, what Yahoo uses, what Bing uses, and even what the open-source Leaflet uses. If you want to make map tiles to use with the most common services, you use Mercator.
Furthermore, should I decide that I absolutely have to use a different projection, I would only have to add two columns to my points database table and do a bunch of one-time calculations.
DISTINCT: Draw only one ambiguous point
If you have two points which are only 10 kilometers apart, then when you are zoomed way in, you might see two different pixels for those two points, but when you zoom out, at some point, the two points will merge and you will only see one pixel. Setting up my drawing routine to only draw the pixel once when drawing points is a big optimization in some circumstances.
Because converting from a VCS coordinate to a pixel coordinate is so lightweight, it can be done easily by MySQL, and the DISTINCT keyword can be used to only return one record for each distinct pixel coordinate.
The DISTINCT keyword is not a big win when drawing polygons, but it is a HUGE, enormous win when drawing points. Drawing points is FAST when I use the DISTINCT keyword, as shown above.
For polygons, you don’t actually want to remove all but one of a given point (as the DISTINCT keyword would do), you want to not draw two successive points that are the same. Doing so is a medium win (shaving about 25% of the time off) for polygon drawing when way zoomed out, but not much of a win when way zoomed in.
Skeletons: Changing the colour palette
While the VCS speed improvement means that I could render most tiles in real time, I still could not render tiles fast enough for a good user experience when the tiles had very large numbers of points. For example, the 2000 Census has 65,322 census tracts; at zoom level 0, that was too many to render fast enough.
Instead, I rendered and saved the geometry into “skeletons”, with one set of skeletons for each jurisdiction type (e.g. census tract, state/province, country, county). Instead of the final colour, I filled the polygons in the skeleton with an ID for the particular jurisdiction corresponding to that polygon. When someone asked for a map showing a particular attribute (e.g. population) and colour mapping, the code would retrieve (or generate) the skeleton, look up each element in the colour palette, decode the jurisdictionId, look up the attribute value for that jurisdictionId (e.g. what is the population for Illinois?), use the colour mapping to get the correct RGBA colour, and write that back to the colour palette. When all the colour palette entries had been updated, I gave it to the requesting browser as a PNG.
While I came up with the idea of fiddling the colour palette independently, it is not unique to me. A friend also came up with this idea independently, for example. What I did was take it a bit farther: I modified the gd libraries so they had a 16-bit colour palette in the skeletons which I wrote to disk. When writing out to PNG, however, my framework uses the standard format. I then created a custom version of PHP which statically linked my custom GD libraries.
(Some people have asked why I didn’t contribute my changes back to gd. It’s because the pieces I changed were of almost zero value to anyone else, while very far-reaching. I knew from testing that my changes didn’t break anything that I needed, but GD has many many features, and I couldn’t be sure that I could make changes in such a fundamental piece of the architecture without causing bugs in far-flung places without way more effort than I was willing to invest.)
More than 64K jurisdictions
16 bits of palette works fine if you have fewer than 64K jurisdictions on a tile (which the 2000 US Census Tract count just barely slid under), but not if you have more than 64K jurisdictions. (At least not with the gd libraries, which don’t reuse a colour palette entry if that colour gets completely overwritten in the image.)
You can instead walk through all the pixels in a skeleton, decode the jurisdiction ID from the pixel colour and rewrite that pixel instead of walking the colour palette. (You need to use a true-colour image if you do that, obviously.) For large numbers of colours, changing the colour palette is no faster than walking the skeleton; it is only a win for small numbers of colours. If you are starting from scratch, it is probably not worth the headache of modifying the graphics library and statically linking in a custom version of GD into PHP to walk the colour palette instead of walking the true-colour pixels.
(I had to modify GD anyway due to a bug I fixed in GD which didn’t get incorporated into the GD release for a very long time. My patch finally got rolled in, so you don’t need to do that yourself.)
My framework now checks to see how many jurisdiction are in the area of interest; if there are more than 64K, it creates a true-colour image, otherwise a paletted image. If the skeleton is true-colour, it walks pixels, otherwise it walks the palette.
Credits: My husband implemented the pixel-walking code.
On-demand skeleton rendering
While I did pre-render about 10-40 tiles per jurisdiction type, I did not render skeletons for the vast majority of tiles. Instead, I render and save a skeleton only when someone asks for it. I saw no sense in rendering ahead of time a high-maginification tile of a rural area. Note that I could only do this on-demand skeleton generation because the VCS speedup made it so fast.
I will also admit that I did generate final tiles (with the colour properly filled in, not a skeleton) to zoom level 8 for some of my most commonly viewed census tract attributes (e.g. population by census tract) with the default value for the colour mapping. I had noticed that people almost never change the colour mapping. I did not need to do this; the performance was acceptable without doing so. It did make things slightly snappier, but mostly it just seemed to me like a waste to repeatedly generate the same tiles. I only did this for US and Australian census jurisdictions.
MySQL vs. PostGIS
One happy sort-of accident is that my ISP, Dreamhost, provides MySQL but does not allow PostGIS. I could have found myself a different ISP, but I was happy with Dreamhost, Dreamhost was cheap, and I didn’t particularly want to change ISPs. This meant that I had to roll my own tools instead of relying upon the more fully-featured PostGiS.
MySQL is kind of crummy for GIS. Its union and intersection operators, for example, use bounding boxes instead of the full polygon. However, if I worked around that, I found that for what I needed to do, MySQL was actually faster (perhaps because it wasn’t paying the overhead of GIS functions that I didn’t need).
PostGIS’ geometries are apparently stored as serialized binary objects, which means that you have to pay the cost of deserializing the object every time you want to look it or one of its constituent elements. I have a table of points, a table of polygons, and a table of jurisdictionIds; I just ask for the points, no deserialization needed. Furthermore, at the time I developed my framework, there weren’t good PHP libraries for deserializing WKB objects, so I would have had to write my own.
Note: not having to deserialize is only a minor win. For most people, the convenience of the PostGIS functions should be worth the small speed penalty.
Database optimization
One thing that I did that was entirely non-sexy was optimizing the MySQL database. Basically, I figured out where there should be indices and put them there. This sped up the code significantly, but it did not take cleverness, just doggedness. There are many other sites which discuss MySQL optimization, so I won’t go into that here.
Future work: Feature-based maps
My framework is optimized for making polygons, but it should be possible to render features very quickly as well. It should be possible to, say, decide to show roads in green, not show mountain elevation, show cities in yellow, and not show city names.
To do this, make a true-colour skeleton where each bit of the pixel’s colour corresponds to the display of a feature. For example, set the least significant bit to 1 if a road is in that pixel. Set the next bit to 1 if there is a city there. Set the next bit to 1 if a city name is displayed there. Set the next bit to 1 if the elevation is 0-500m. Set the next bit to 1 if the elevation is 500m-1000m. Etc. You then have 32 feature elements
which you can turn on and off by adjusting your colour mapping function.
If you need more than 32 feature elements, then you could use two skeletons and merge the images after you do the colour substitutions.
You could also, if you chose, store elevation (or depth) in the pixel, and adjust the colouring of the elevation with your colour mapping function.
Addendum: I meant to mention, but forgot, UTFGrid. UTFGrid has an array backing the tile for lookup of features, so it is almost there. However, it is just used to make pop-up windows, not (as near as I can tell) to colour polygons.
Permalink
01.02.10
Posted in Hacking at 3:39 pm by ducky
I was talking to a friend of mine who I’m guessing was born in the late 1970s, and mentioned that I had been using computers since 1968ish and email since 1974. (Yes, really.)
I saw a lightbulb go off over his head. He knew I was in my mid-forties, and knew I was a computer geek, but hadn’t ever really put two and two together. “Oh! You were around for the start of the personal computer revolution? What was that like? That must have been totally *COOL*!!!”
I said, “Not really.”
He was stunned. How could it have possibly not been totally cool and awesome? I could see him struggling with trying to figure out how to express his confusion, how to figure out what question to even ask.
I said, “Look. You are old enough that you were around for the start of the mobile phone revolution, right? That must have been totally *COOL*!!!”
“Oh”, he said. “I get it.”
Mobile phones, when they first started out were kind of cool, I guess, but they weren’t “magic” then: they took real effort and patience. They were wickedly expensive, heavy, had lousy user interfaces, and you had to constantly worry about whether you had enough battery life for the call. The reception was frequently (usually?) poor, so even if you could make a connection, your call frequently got dropped. The signal quality was poor, so you had to TALK LOUDLY to be heard and really concentrate to understand the other person. And they didn’t do much. It took a long time for mobile phones to become “magic”, and they only got better incrementally.
When they first came out, personal computers were kind of cool, I guess, but they weren’t “magic” then: they took real effort and patience. They were wickedly expensive. They crashed frequently enough that you always had to worry about saving your work. They had so little disk space that managing your storage was a constant struggle (and why floppies held on for so very long after the introduction of the hard drive).
When I started my first job out of college (working at a DRAM factory for Intel in 1984), they had only recently put in place two data-entry clerks to input information about the materials (“lots”) as the lots traversed the manufacturing plant. (When did the lot arrive at a processing step? When did it get processed? Who processed it? What were the settings and reading on the machine?) However, to get at that information, engineers like me had to get a signature from higher level of management to authorize a request to MIS (which might get turned down!) for that information.
A few months after I started, they bought three IBM PC XTs and put them in a cramped little room for us engineers to use. I believe the only programs on them were a word processor and a spreadsheet. There was no storage available to us. They had hard drives, but we were not allowed to leave anything on the hard drive; we had to take our work away on floppies. The PCs were not networked, so not only was there no email (and of course no Web), but no way to access the data that was collected out on the manufacturing floor.
If I wanted to make a spreadsheet analyzing e.g. the relationship between measured thickness of the aluminum layer, the measured sputtering voltage, and how long it had been since the raw materials had been replenished, I would go to the factory floor, walk around to find different lots in different stages of processing, copy the information to a piece of paper, take the piece of paper and a floppy disk to the computer room (hoping that there was a free computer), copy the data from the piece of paper into the spreadsheet, print the spreadsheet (maybe making a graph, but that was a little advanced), and copy the data onto my floppy if I wanted to look at it again.
Even though we “had computers”, we had no network, no email, and no wiki. The way I shared information was still:
- make a bunch of photocopies and put them in people’s (physical) mailboxes,
- make a bunch of photocopies and walk around putting them on people’s desks,
- make a bunch of photocopies and pass them out at a meeting where I presented my results, or
- make one photocopy, write a routing list on it (a list of names with checkboxes), and put it on the first person’s desk. They would read it, check their name off, and pass it to someone else on the list.
At the next company I worked at (1985-7), I got a PC on my desk because I was implementing the materials tracking system (because I had bitched about how stupid it was not to have one — yeah!!). Our company had a network, but it was expensive and complicated enough that my desktop computer wasn’t on the network, nor were the two machines on the floor. Ethernet used a coax cable and (if I recall correctly) you had to make a physical connection by puncturing the cable just right. The configuration was tricky and not very fault-tolerant: if one computer on the network was misconfigured, it would mess up the entire network AND it was difficult even for a skilled network technician to figure out which computer was misconfigured.
At the next company I worked for (1987), I had a Sun workstation on my desk, and we had a network file servers, but I don’t think we used email, even internally.
At my next company (1988-90), I had a Wyse 50 “glass teletype” on my desktop and full email capability. The Wyse 50 didn’t have any graphics, but that wasn’t a real big deal because no programs I would ever want to use at work had graphics of any sort. My department used email heavily, but there were some departments in the company that did not use email, so there were lots of memos that were still issued on paper. They would go either into my (physical) mailbox, or would be pinned to cubicle corridor walls.
While I had the theoretical ability to send email to the outside world then, almost nobody I knew outside the company had email, and figuring out how to address messages to get to the outside was difficult: you had to specify all the intermediate computers, e.g. sun!ubc!decwrl!decshr!slaney.
It wasn’t until that company imploded in about 1990 and my colleagues scattered to other computer companies that I had anyone outside my company to correspond with. (Fortunately, at about the same time, it got easier to address external email messages.)
It wasn’t until 1991 that I stopped seeing paper memos — a full twenty fifteen years after the introduction of the Apple II computer. My husband reports that he also stopped seeing paper memos in about 1991.
I would contend that computers didn’t really start to become “magic” until about 1996 or so, when the World Wide Web had been absorbed by the masses and various Web services were available. Only after about 1996 could you pretty reliably assume that anyone (well, those born after WW2 started, at least) used computers or had an email address.
So when personal computers first came out, they were not totally cool. The idea of personal computers was totally cool. The potential was totally cool. But that potential was unrealized for many many years.
Permalink
08.15.09
Posted in Hacking, Maps at 9:54 pm by ducky
It might not look like I have done much with my maps in a while, but I have been doing quite a lot behind the scenes.
Census Tracts
I am thrilled to say that I now have demographic data at the census tract level now on my electoral map! Unlike my old demographic maps (e.g. my old racial demographics map), the code is fast enough that I don’t have to cache the overlay images. This means that I can allow people to zoom all the way out if they choose, while before I only let people zoom back to zoom level 5 (so you could only see about 1/4 of the continental US at once).
These speed improvements were not easy, and it’s still not super-fast, but it is acceptable. It takes between 5-30 seconds to show a thematic map for 65,323 census tracts. (If you think that is slow, go to Geocommons, the only other site I’ve found to serve similarly complex maps on-the-fly. They take about 40 seconds to show a thematic map for the 3,143 counties.)
A number of people have suggested that I could make things faster by aggregating the data — show things per-state when way zoomed out, then switch to per-county when closer in, then per-census tract when zoomed in even more. I think that sacrifices too much. Take, for example, these two slices of a demographic map of the percent of the population that is black. The %black by county is on the left, the %black by census tract is on the right. The redder an area is, the higher the percentage of black people is.

Percent of population that is black; by counties on left, by census tracts on the right
You’ll notice that the map on the right makes it much clearer just how segregated black communities are outside of the “black belt” in the South. It’s not just that black folks are a significant percentage of the population in a few Northern counties, they are only significantly present in tiny little parts of Northern counties. That’s visible even at zoom level 4 (which is the zoom level that my electoral map opens on). Aggregating the data to the state level would be even more misleading.
Flexibility
Something else that you wouldn’t notice is that my site is now more buzzword-compliant! When I started, I hard-coded the information layers that I wanted: what the name of the attribute was in the database (e.g. whitePop), what the English-language description was (e.g. “% White”), what colour mapping to use, and what min/max numeric values to use. I now have all that information in an XML file on the server, and my client code calls to the server to get the information for the various layers with AJAX techniques. It is thus really easy for me to insert a new layer into a map or even to create a new map with different layers on it. (For example, I have dithered about making a map that shows only the unemployment rate by county, for each of the past twelve months.)
Some time ago, I also added the ability for me to specify how to calcualte a new number with two different attributes. Before, if I wanted to plot something like %white, I had to add a column to the database of (white population / total population) and map that. Instead, I added the ability to do divisions on-the-fly. Subtracting two attributes was also obviously useful for things like the difference in unemployment from year to year. While I don’t ever add two attributes together yet, I can see that I might want to, like to show the percentage of people who are either Evangelical or Morman. (If you come up with an idea for how multiplying two attributes might be useful, please let me know.)
Loading Data
Something else that isn’t obvious is that I have developed some tools to make it much easier for me to load attribute data. I now use a data definition file to spell out the mapping between fields in an input data file and where the data should go in the database. This makes it much faster for me to add data.
The process still isn’t completely turnkey, alas, because there are a million-six different oddnesses in the data. Here are some of the issues that I’ve faced with data that makes it non-straightforward:
- Sometimes the data is ambiguous. For example, there are a number of states that have two jurisdictions with the same name. For example, the census records separately a region that has Bedford City, VA and Bedford County, VA. Both are frequently just named “Bedford” in databases, so I have to go through by hand and figure out which Bedford it is and assign the right code to it. (And sometimes when the code is assigned, it is wrong.)
- Electoral results are reported by county everywhere except Alaska, where they are reported by state House district. That meant that I had to copy the county shapes to a US federal electoral districts database, then delete all the Alaskan polygons, load up the state House district polygons, and copy those to the US federal electoral districts database.
- I spent some time trying to reverse-engineer the (undocumented) Census Bureau site so that I could automate downloading Census Bureau data. No luck so far. (If you can help, please let me know!) This means that I have to go through an annoyingly manual process to download census tract attributes.
- Federal congressional districts have names like “CA-32” and “IL-7”, and the databases reflect that. I thought I’d just use the state jurisdiction ID (the FIPS code, for mapping geeks) for two digits and two digits for the district ID, so CA-32 would turn into 0632 and IL-7 would turn into 1707. Unfortunately, if a state has a small enough population, they only get one congressional rep; the data file had entries like “AK-At large” which not only messed up my parsing, but raised the question of whether at-large congresspeople should be district 0 or district 1. I scratched my head and decided assign 0 to at-large districts. (So AK-At large became 0200.) Well, I found out later that data files seem to assign at-large districts the number 1, so I had to redo it.
None of these data issues are hard problems, they are just annoying and mean that I have to do some hand-tweaking of the process for almost every new jurisdiction type or attribute. It also takes time just to load the data up to my database server.
I am really excited to get the on-the-fly census tract maps working. I’ve been wanting it for about three years, and working on it off and on (mostly off) for about six months. It really closes a chapter for me.
Now there is one more quickie mapping application that I want to do, and then I plan to dive into adding Canadian information. If you know of good Canadian data that I can use freely, please let me know. (And yes, I already know about GeoGratis.)
Permalink
05.20.09
Posted in Hacking, programmer productivity, robobait, Technology trends at 11:44 am by ducky
I had a very brief but very interesting talk with Prof. Margaret Burnett. She does research on gender and programming. at Oregon State University, but was in town for the International Conference on Software Engineering. She said that many studies have shown that women are — in general — more risk averse than men are. (I’ve also commented on this.) She said that her research found that risk-averse people (most women and some men) are less likely to tinker, to explore, to try out novel features in both tools and languages when programming.
I extrapolate that this means that risk-seeking people (most men and some women) were more likely to have better command of tools, and this ties into something that I’ve been voicing frustration with for some time — there is no instruction on how to use tools in the CS curriculum — but I had never seen it as a gender-bias issue before. I can see how a male universe would think there was no need to explain how to use tools because the figured that the guys would just figure it out on their own. And the most guys might — but most of the women and some of the men might not figure out how to use tools on their own.
In particular, there is no instruction on how to use the debugger: not on what features are available, not on when you should use a debugger vs. not, and none on good debugging strategy. (I’ve commented on that here.) Some of using the debugger is art, true, but there are teachable strategies – practically algorithms — for how to use the debugger to achieve specific ends. (For example, I wrote up how to use the debugger to localize the causes of hangs.)
Full of excitement from Prof. Burnett’s revelations, I went to dinner with a bunch of people connected to the research lab I did my MS research in. All men, of course. I related how Prof. Burnett said that women didn’t tinker, and how this obviously implied to me that CS departments should give some instruction on how to use tools. The guys had a different response: “The departments should teach the women how to tinker.”
That was an unsatisfying response to me, but it took me a while to figure out why. It suggests that the risk-averse pool doesn’t know how to tinker, while in my risk-averse model, it is not appropriate to tinker: one shouldn’t goof off fiddling with stuff that has a risk of not being useful when there is work to do!
(As a concrete example, it has been emotionally very difficult for me to write this blog post today. I think it is important and worthwhile, but I have a little risk-averse agent in my head screaming, screaming at me that I shouldn’t be wasting my time on this: I should be applying for jobs, looking for an immigration lawyer, doing laundry, or working on improving the performance of my maps code. In other words, writing this post is risky behaviour: it takes time for no immediate payoff, and only a low chance of a future payoff. It might also be controversial enough that it upsets people. Doing laundry, however, is a low-risk behaviour: I am guaranteed that it will make my life fractionally better.)
To change the risk-averse population’s behaviour, you would have to change their entire model of risk-reward. I’m not sure that’s possible, but I also think that you shouldn’t want to change the attitude. You want some people to be risk-seeking, as they are the ones who will get you the big wins. However, they will also get you the big losses. The risk-averse people are the ones who provide stability.
Also note that because there is such asymmetry in task completion time between above-median and below-median, you might expect that a bunch of median programmers are, in the aggregate, more productive than a group at both extremes. (There are limits to how much faster you can get at completing a task, but there are no limits to how much slower you can get.) It might be that risk aversion is a good thing!
There was a study I heard of second-hand (I wish I had a citation — anybody know?) that found that startups with a lot of women (I’m remembering 40%) had much MUCH higher survival rates than ones with lower proportions of women. This makes perfect sense to me; a risk-averse population would rein in the potentially destructive tendencies of a risk-seeking population.
Thus I think it does make sense to provide academic training in how to use tools. This should perhaps be coupled with some propaganda about how it is important to set aside some time in the future to get comfortable with tools. (Perhaps it should be presented as risky to not spend time tinkering with tools!)
UPDATE: There’s an interesting (though all-too-brief!) article that mentions differences in the biochemical responses to risk that men and women produce. It says that men produce adrenaline, which is fun. Women produce acetylcholine, which the article says pretty much makes them want to vomit. That could certainly change one’s reaction to risk..
Permalink
04.21.09
Posted in Canadian life, Hacking, University life at 11:47 am by ducky
The UBC programming team took 34th place at the 2009 International Collegiate Programming Contest (ICPC) World Finals in Stockholm! W00t!!
This marks the sixth year in a row that UBC has gone to the World Finals, despite being entirely undergraduates and entirely without World Finals experience. (We have information on past teams, but don’t know the seniority of the 2004 team.)
Congratulations, team!
Permalink
« Previous entries Next Page » Next Page »

